使用 Cluster Capacity 來預覽 Pod 的部署情況
本篇文章介紹一個可以用來評估目前叢集資源能夠部署多少個目標 Pod 的工具,同時也可以透過該工具來預覽一下可能的分佈情形
目的
根據 Cluster Capacity 當初的設計文件,其目的就是
The goal is to provide a framework that estimates a number of instances of a specified pod that would be scheduled in a cluster.
根據解讀,就是根據當前 Cluster 的系統資源量來評估目標 Pod 最多可以部署到多少個到環境中,同時每個節點上最多可以有幾個。
此外該工具除了用來計算總量外,還可以用來預覽目標 Pod 可能會被部署到哪些節點上,對於用來學習 Taint/Toleration, NodeSelector, PodAntiAffintiy 來說也是一個不差的工具,雖然並非完美到可以完全模擬 Scheduler 的行為但是整體上也不差了。
環境建置
該工具的 Github 並沒有提供編譯好的執行檔案,因此要使用的話一種就是自行下載編譯,不然就是使用官方提供的 Container Image,本篇範例以下載自行編譯為主
$ git clone https://github.com/openshift/cluster-capacity.git
$ cd cluster-capacity
$ make
GO111MODULE=auto go build -o hypercc sigs.k8s.io/cluster-capacity/cmd/hypercc
ln -sf hypercc cluster-capacity
ln -sf hypercc genpod
$ ./cluster-capacity
Pod spec file is missing
Cluster-capacity simulates an API server with initial state copied from the Kubernetes enviroment
with its configuration specified in KUBECONFIG. The simulated API server tries to schedule the number of
pods specified by --max-limits flag. If the --max-limits flag is not specified, pods are scheduled until
the simulated API server runs out of resources.
Usage:
cluster-capacity --kubeconfig KUBECONFIG --podspec PODSPEC [flags]
Flags:
--default-config string Path to JSON or YAML file containing scheduler configuration.
--exclude-nodes strings Exclude nodes to be scheduled
-h, --help help for cluster-capacity
--kubeconfig string Path to the kubeconfig file to use for the analysis.
--max-limit int Number of instances of pod to be scheduled after which analysis stops. By default unlimited.
-o, --output string Output format. One of: json|yaml (Note: output is not versioned or guaranteed to be stable across releases).
--podspec string Path to JSON or YAML file containing pod definition.
--verbose Verbose mode
Note: 環境需要安裝 make 以及 golang 相關工具才可以正確編譯
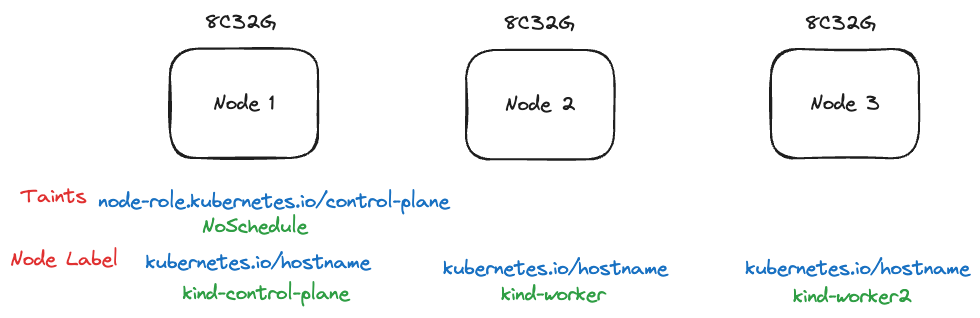
範例環境使用 KIND 去搭建一個三節點的機器,每個節點所觀看到的資源量都為 4C32G
- 每個節點都有一個 key 為 "kubernetes.io/hostname" 的 node label, value 為各自的名稱
- 第一個節點有一個 taint, key 為 "node-role.kubernetes.io/control-plane"
之後的範例就是會基於這個環境來嘗試各種 cluster-capacity 工具的用法
概念如下圖
系統資源評估
準備下列 pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: small-pod
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google-samples/gb-frontend:v4
imagePullPolicy: Always
resources:
limits:
cpu: 150m
memory: 100Mi
requests:
cpu: 150m
memory: 100Mi
restartPolicy: "OnFailure"
dnsPolicy: "Default"
該 Pod 需要關注的點有兩個
- 有描述需要的 CPU 以及 Memory 用量
- 沒有描述任何跟指派(NodeSelector...etc)有關的設定
接下來執行. cluster-capacity 來觀察其結果
$ ./cluster-capacity --kubeconfig ~/.kube/config --podspec examples/pod.yaml --verbose
small-pod pod requirements:
- CPU: 150m
- Memory: 100Mi
The cluster can schedule 104 instance(s) of the pod small-pod.
Termination reason: Unschedulable: 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 Insufficient cpu. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod.
Pod distribution among nodes:
small-pod
- kind-worker2: 52 instance(s)
- kind-worker: 52 instance(s)
該結果我們分成幾個部分來拆解 首先描述目標 Pod 關於資源用量的需求
small-pod pod requirements:
- CPU: 150m
- Memory: 100Mi
接者明確指出,目前 cluster 最多可以部署 104 個目標 Pod
The cluster can schedule 104 instance(s) of the pod small-pod.
接者指出為什麼沒有辦法部署更多的 Pod,原因大致上是
- 有一個 Node 有 Taint,因此不能被考慮
- 剩下兩個 Node 沒有足夠的 CPU
Termination reason: Unschedulable: 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 Insufficient cpu. preemption: 0/3 nodes are available: 1 Preemption is not helpful for scheduling, 2 No preemption victims found for incoming pod.
最後呈現104的 Pod 的計算分佈
Pod distribution among nodes:
small-pod
- kind-worker2: 52 instance(s)
- kind-worker: 52 instance(s)
以 kinde-wokrer 當下的資源分佈情況
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 100m (1%) 100m (1%)
memory 50Mi (0%) 50Mi (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
理論上有 8C32G 的資源用量,扣掉上述佔用資源後,剩下 7.9C, 31.95G,而每個目標需要 0.15C,計算後可以得到 7.9/0.15 ~= 52.6666,因此最多就是 52 個節點。
透過上述的範例,可以清楚地看到 cluster-capacity 此工具快速的計算
- 該 Pod 只能部署到 kind-worker 以及 kind-worker2 這兩個節點,這也符合預期,因為第一個節點有 Taint
- 上述每個節點考慮到當前資源量後,各自最多只能部署 52 個副本,整個 cluster 最多 104 個副本。
Taint/Toleration
接下來嘗試加入 Toleration 讓目標 Pod 可以部署到第一個節點,這時候 Pod YAML 如下,並且存為 pod2.yaml
apiVersion: v1
kind: Pod
metadata:
name: small-pod
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google-samples/gb-frontend:v4
imagePullPolicy: Always
resources:
limits:
cpu: 150m
memory: 100Mi
requests:
cpu: 150m
memory: 100Mi
tolerations:
- key: "node-role.kubernetes.io/control-plane"
effect: "NoSchedule"
restartPolicy: "OnFailure"
dnsPolicy: "Default"
執行 cluster-capacity 工具可以觀察到
$ ./cluster-capacity --kubeconfig ~/.kube/config --podspec examples/pod2.yaml --verbose
small-pod pod requirements:
- CPU: 150m
- Memory: 100Mi
The cluster can schedule 151 instance(s) of the pod small-pod.
Termination reason: Unschedulable: 0/3 nodes are available: 3 Insufficient cpu. preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
Pod distribution among nodes:
small-pod
- kind-worker: 52 instance(s)
- kind-worker2: 52 instance(s)
- kind-control-plane: 47 instance(s)
可以觀察到這時候 kind-control-plane 節點也被納入考慮,考慮到目前節點上目前剩下的資源用量, 7.05C, 29.1G 下去分配,7.05/0.15 = 47 也符合預期的 47 個副本。
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 950m (11%) 100m (1%)
memory 290Mi (0%) 390Mi (1%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
NodeSelector
接下來嘗試使用 NodeSelector 來指派固定一個節點,將下列檔案存為 pod3.yaml
apiVersion: v1
kind: Pod
metadata:
name: small-pod
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google-samples/gb-frontend:v4
imagePullPolicy: Always
resources:
limits:
cpu: 150m
memory: 100Mi
requests:
cpu: 150m
memory: 100Mi
nodeSelector:
kubernetes.io/hostname: kind-worker2
tolerations:
- key: "node-role.kubernetes.io/control-plane"
effect: "NoSchedule"
restartPolicy: "OnFailure"
dnsPolicy: "Default"
運行 cluster-capctiy 可觀察到
$ ./cluster-capacity --kubeconfig ~/.kube/config --podspec examples/pod3.yaml --verbose
small-pod pod requirements:
- CPU: 150m
- Memory: 100Mi
- NodeSelector: kubernetes.io/hostname=kind-worker2
The cluster can schedule 52 instance(s) of the pod small-pod.
Termination reason: Unschedulable: 0/3 nodes are available: 1 Insufficient cpu, 2 node(s) didn't match Pod's node affinity/selector. preemption: 0/3 nodes are available: 1 No preemption victims found for incoming pod, 2 Preemption is not helpful for scheduling.
Pod distribution among nodes:
small-pod
- kind-worker2: 52 instance(s)
這時候的結果就只有針對目標節點去計算,結果也符合預期
AntiPodAffinity
接下來嘗試使用 AntiPodAffinity,這部分需要先部署 pod3.yaml 到環境內來打造 AntiPod 的環境
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
small-pod 0/1 ErrImagePull 0 5s 10.244.2.2 kind-worker2 <none> <none>
當 Pod 部署完畢後,接下來準備下列的 Pod YAML,並且存放到 pod4.yaml
apiVersion: v1
kind: Pod
metadata:
name: small-pod
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google-samples/gb-frontend:v4
imagePullPolicy: Always
resources:
limits:
cpu: 150m
memory: 100Mi
requests:
cpu: 150m
memory: 100Mi
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- guestbook
topologyKey: "kubernetes.io/hostname"
tolerations:
- key: "node-role.kubernetes.io/control-plane"
effect: "NoSchedule"
restartPolicy: "OnFailure"
dnsPolicy: "Default"
該檔案透過 Affinty.podAntiAffinity.requiredDuringSchedulingIgnoredDuringExecution 確保該 Pod 必須要跟前述的 Pod 給分開。
# ./cluster-capacity --kubeconfig ~/.kube/config --podspec examples/pod4.yaml --verbose
small-pod pod requirements:
- CPU: 150m
- Memory: 100Mi
The cluster can schedule 99 instance(s) of the pod small-pod.
Termination reason: Unschedulable: 0/3 nodes are available: 1 node(s) didn't match pod anti-affinity rules, 2 Insufficient cpu. preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
Pod distribution among nodes:
small-pod
- kind-worker: 52 instance(s)
- kind-control-plane: 47 instance(s)
可以觀察到執行的結果,也有正確的排除 worker2,因為 worker2 上有 antiAffinity 的規則影響,因此最後只有 kind-worker 與 kind-control-plane 兩個節點可以用
Summary
Cluster-Capacity 工具設計的目的是提供一個方式讓使用者可以去評估目標 Pod 最多可以於目標 Cluster 內部署多少個副本,為了計算這個數量,跟指派相關的功能,如 NodeSelector, Taint/Toleration 等也需要被考慮進來,因此也可以當作一個簡單的工具來預覽一下 Pod 部署後可能座落於哪些節點上。