Apache Kafka — 外部整合
分析版本
本文件基於 commit 7b8549f3 進行分析。
Kafka Connect 連接器生態系
Kafka Connect 透過開放的 Connector API,支援豐富的第三方連接器生態系:
常見 Source Connectors
| Connector | 說明 | 維護者 |
|---|---|---|
| Debezium | CDC(Change Data Capture)連接器,支援 MySQL、PostgreSQL、MongoDB 等 | Debezium / Red Hat |
| JDBC Source | 從關聯式資料庫讀取資料(polling 或 timestamp-based) | Confluent |
| Salesforce | 從 Salesforce 攝取 CRM 資料 | Confluent |
| S3 Source | 從 Amazon S3 讀取檔案 | Confluent |
| Twitter / X | 從 Twitter Streaming API 攝取推文 | 社群 |
常見 Sink Connectors
| Connector | 說明 | 維護者 |
|---|---|---|
| S3 Sink | 將 Kafka 訊息寫入 Amazon S3(Parquet/JSON/CSV/Avro) | Confluent |
| JDBC Sink | 將 Kafka 訊息寫入關聯式資料庫 | Confluent |
| Elasticsearch Sink | 將 Kafka 訊息寫入 Elasticsearch | Confluent |
| BigQuery Sink | 將 Kafka 訊息寫入 Google BigQuery | WePay / Confluent |
| HDFS 3 Sink | 將 Kafka 訊息寫入 Hadoop HDFS | Confluent |
| MongoDB Sink | 將 Kafka 訊息寫入 MongoDB | MongoDB |
| Cassandra Sink | 將 Kafka 訊息寫入 Apache Cassandra | DataStax |
| Snowflake Sink | 將 Kafka 訊息寫入 Snowflake Data Warehouse | Snowflake |
Connect REST API
Kafka Connect 提供完整的 REST API(預設埠 :8083)用於管理連接器:
| 端點 | 方法 | 說明 |
|---|---|---|
/connectors | GET | 列出所有 Connector |
/connectors | POST | 建立 Connector |
/connectors/{name} | GET | 取得 Connector 設定 |
/connectors/{name} | PUT | 更新 Connector 設定 |
/connectors/{name} | DELETE | 刪除 Connector |
/connectors/{name}/status | GET | 取得 Connector 與 Task 狀態 |
/connectors/{name}/pause | PUT | 暫停 Connector |
/connectors/{name}/resume | PUT | 恢復 Connector |
/connectors/{name}/restart | POST | 重啟 Connector |
/connectors/{name}/tasks | GET | 列出所有 Task |
/connectors/{name}/tasks/{taskId}/status | GET | 取得 Task 狀態 |
Connect Worker 部署模式
Standalone 模式(適用開發/測試):
bash
./bin/connect-standalone.sh config/connect-standalone.properties connector1.propertiesDistributed 模式(生產環境):
bash
./bin/connect-distributed.sh config/connect-distributed.propertiesDistributed 模式下,多個 Worker 組成一個 Connect Cluster,透過 Kafka Topic 共享設定與位移。
MirrorMaker 2(MM2)
MirrorMaker 2(connect/mirror/)是 Kafka 的跨叢集資料複製解決方案,基於 Kafka Connect 架構實作。
MM2 架構
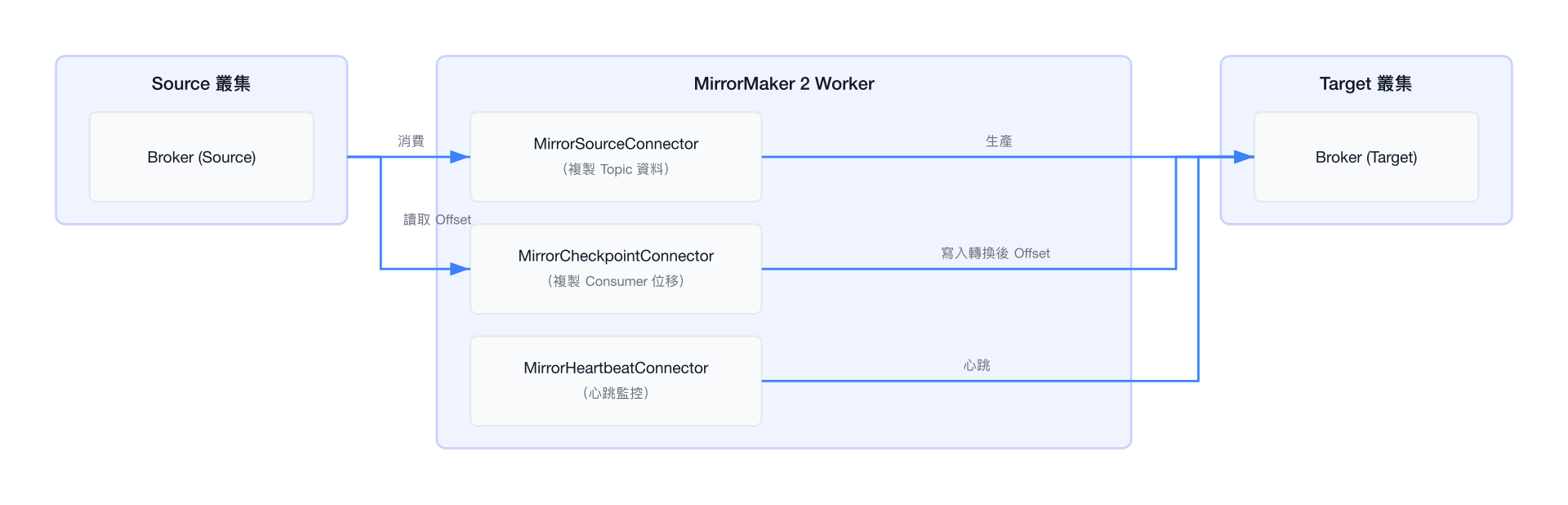
MM2 主要特性
| 特性 | 說明 |
|---|---|
| Topic 命名規則 | 目標叢集上的 Topic 自動加上來源叢集前綴(如 us-west.my-topic) |
| Consumer Offset 轉換 | 自動將來源叢集位移轉換至目標叢集對應位移 |
| 雙向複製 | 支援 Active-Active 雙向複製(需注意 Topic 命名衝突) |
| Topic 過濾 | 透過正則表達式控制複製哪些 Topic |
| 設定同步 | 可同步 Topic 設定(如 retention.ms) |
Schema Registry 整合
雖然 Schema Registry 不是 Kafka 核心專案(由 Confluent 開發),但 Kafka 生態系中廣泛使用它管理 Avro/JSON/Protobuf Schema:
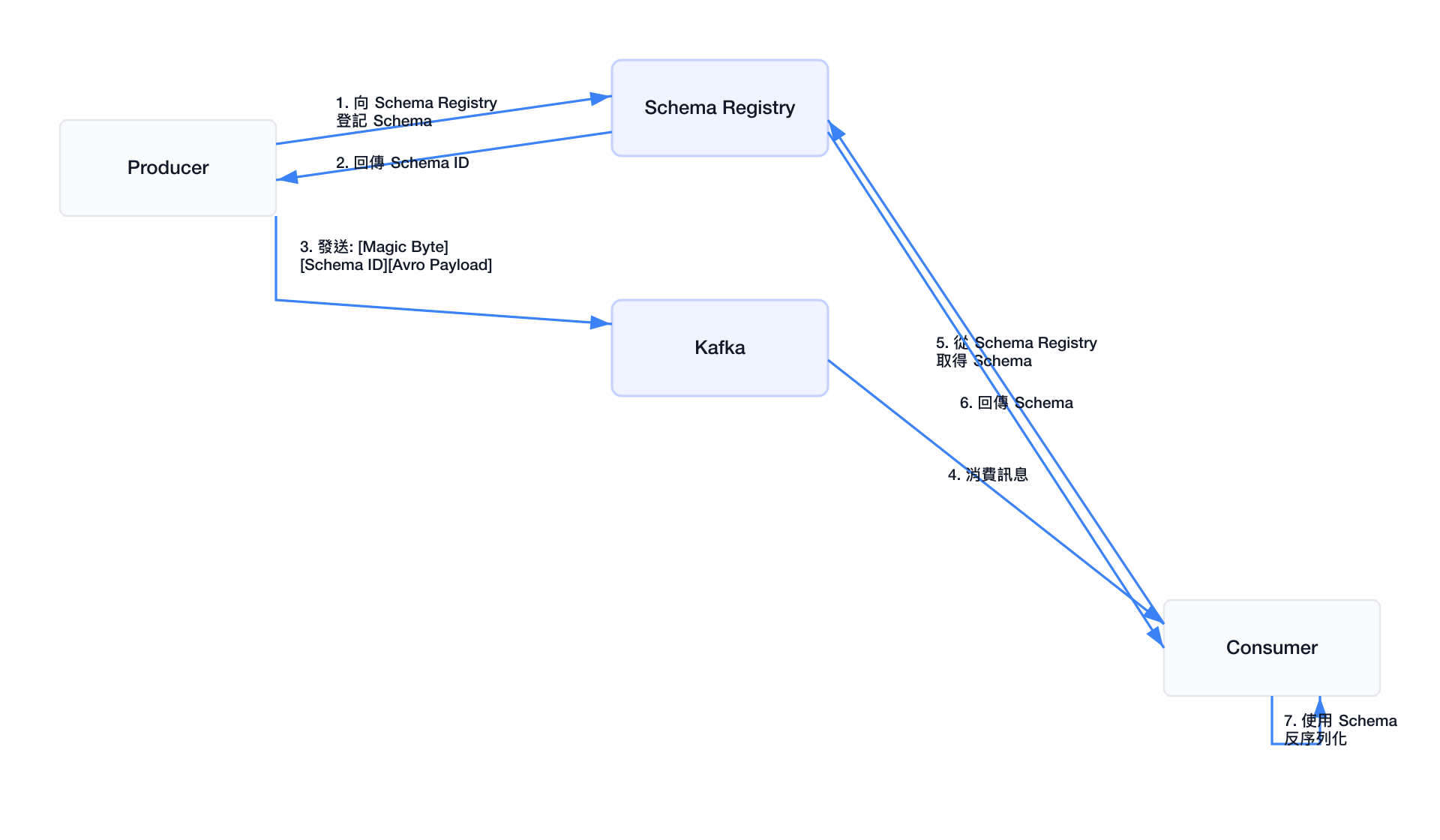
監控整合(JMX / Prometheus)
JMX 指標
Kafka 原生提供豐富的 JMX(Java Management Extensions) 指標,可透過 JConsole、JMXTerm 或 Prometheus JMX Exporter 存取:
| MBean 分類 | 說明 |
|---|---|
kafka.server:type=BrokerTopicMetrics | Topic 層級的訊息數、位元組數統計 |
kafka.server:type=ReplicaManager | ISR 收縮/擴張次數、Leader 數量 |
kafka.server:type=KafkaRequestHandlerPool | 請求處理執行緒利用率 |
kafka.network:type=RequestMetrics | 各 API 的請求延遲(50/95/99 百分位) |
kafka.log:type=LogFlushStats | Log Flush 頻率與延遲 |
kafka.controller:type=KafkaController | 離線 Partition 數量、Active Controller 狀態 |
Prometheus JMX Exporter 整合
yaml
# jmx_exporter 設定(kafka-jmx-exporter.yml 範例)
rules:
- pattern: kafka.server<type=BrokerTopicMetrics, name=MessagesInPerSec><>OneMinuteRate
name: kafka_server_brokertopicmetrics_messagesinpersec
- pattern: kafka.network<type=RequestMetrics, name=RequestsPerSec, request=(\w+)><>OneMinuteRate
name: kafka_network_requestmetrics_requestspersec
labels:
request: "$1"關鍵監控指標
| 指標 | 告警閾值建議 | 說明 |
|---|---|---|
UnderReplicatedPartitions | > 0 | ISR 副本不足的 Partition 數量 |
OfflinePartitionsCount | > 0 | 離線(無 Leader)的 Partition 數量 |
ActiveControllerCount | != 1 | 叢集中 Active Controller 數量 |
RequestHandlerAvgIdlePercent | < 20% | 請求處理執行緒空閒率(過低表示 CPU 瓶頸) |
NetworkProcessorAvgIdlePercent | < 30% | 網路執行緒空閒率 |
BytesInPerSec / BytesOutPerSec | - | 網路吞吐量 |
consumer-fetch-manager-metrics: records-lag-max | > 閾值 | Consumer Lag 最大值 |
Docker 與 Kubernetes 部署
Docker 官方映像
bash
# 使用官方 Docker 映像啟動單節點 Kafka(KRaft 模式)
docker run -p 9092:9092 apache/kafka:4.0.0
# 使用 docker-compose 啟動 3 節點叢集
docker compose -f docker/examples/jvm/docker-compose.yml updocker/ 目錄包含官方 Dockerfile 與 docker-compose 範例。
Kubernetes 部署選項
| 工具 | 說明 |
|---|---|
| Strimzi | 開源 Kafka Operator,支援完整生命週期管理(包含 KRaft) |
| Confluent Operator | 商業版 Kafka Operator(Confluent Platform) |
| Helm Charts | bitnami/kafka Helm Chart(社群維護) |
| KRaft on K8s | 直接使用 StatefulSet 部署 KRaft 叢集 |