Monitoring — 核心功能分析
本頁深入分析 kubevirt/monitoring 專案的五大核心功能:告警 Runbook、Prometheus 指標、Grafana 儀表板、指標 Linter 工具,以及指標文件生成器。
告警 Runbook
docs/runbooks/ 目錄收錄了 73 份 告警 Runbook,每份對應一條 Prometheus 告警規則,提供統一的四段式排錯指南。
Runbook 格式
每份 Runbook 嚴格遵循以下結構:
# <AlertName>
## Meaning ← 告警觸發的條件與背景說明
## Impact ← 對叢集/虛擬機的影響程度
## Diagnosis ← 逐步診斷命令(kubectl / systemctl / journalctl)
## Mitigation ← 修復步驟與參考資源連結來源路徑
monitoring/docs/runbooks/*.md — 每個 .md 檔案對應一條告警規則
Runbook 分類
| 分類 | 數量 | 代表 Runbook |
|---|---|---|
| KubeVirt 核心元件 | ~25 | VirtAPIDown, VirtControllerDown, VirtHandlerDown, VirtOperatorDown, NoReadyVirtAPI, NoReadyVirtController, LowReadyVirtHandlerCount |
| 虛擬機 (VM/VMI) | ~12 | KubeVirtVMIExcessiveMigrations, KubeVirtNoAvailableNodesToRunVMs, VMCannotBeEvicted, OrphanedVirtualMachineInstances, OutdatedVirtualMachineInstanceWorkloads |
| CDI(儲存匯入) | 8 | CDIDataImportCronOutdated, CDINotReady, CDIOperatorDown, CDIStorageProfilesIncomplete, CDINoDefaultStorageClass |
| HCO(超融合管理) | 6 | HCOInstallationIncomplete, HCOOperatorConditionsUnhealthy, UnsupportedHCOModification, HCOMisconfiguredDescheduler |
| SSP(排程/效能/範本) | 5 | SSPCommonTemplatesModificationReverted, SSPDown, SSPFailingToReconcile, SSPHighRateRejectedVms, SSPTemplateValidatorDown |
| CNAO(網路附加元件) | 3 | CnaoDown, CnaoNmstateMigration, NetworkAddonsConfigNotReady |
| HPP(HostPath Provisioner) | 3 | HPPOperatorDown, HPPNotReady, HPPSharingPoolPathWithOS |
| 網路 | 2 | NodeNetworkInterfaceDown, KubemacpoolDown |
| 其他 | ~9 | DeprecatedMachineType, HighCPUWorkload, PersistentVolumeFillingUp, GuestFilesystemAlmostOutOfSpace |
範例 Runbook 1:KubeVirtVMIExcessiveMigrations
# KubeVirtVMIExcessiveMigrations
## Meaning
此告警在虛擬機實例 (VMI) 於 24 小時內遷移超過 12 次時觸發。
此遷移率即使在升級期間也屬異常偏高,可能代表叢集基礎設施問題。
## Impact
頻繁遷移的 VM 可能因記憶體分頁錯誤而效能下降。
## Diagnosis
1. 驗證 worker 節點是否有足夠資源:
$ kubectl get nodes -l node-role.kubernetes.io/worker= -o json \
| jq .items[].status.allocatable
2. 檢查 worker 節點狀態(MemoryPressure / DiskPressure / PIDPressure)
3. 登入節點確認 kubelet 服務運行中:$ systemctl status kubelet
4. 檢查 kubelet 日誌:$ journalctl -r -u kubelet
## Mitigation
確保 worker 節點有足夠 CPU / 記憶體 / 磁碟資源以無中斷運行 VM 工作負載。來源
monitoring/docs/runbooks/KubeVirtVMIExcessiveMigrations.md
範例 Runbook 2:CDIDataImportCronOutdated
# CDIDataImportCronOutdated
## Meaning
DataImportCron 無法輪詢或匯入最新磁碟映像版本。
DataImportCron 會輪詢磁碟映像以檢查最新版本,並匯入至 PVC 或
VolumeSnapshot,確保 golden image 保持最新。
## Impact
- VM 可能以過時的磁碟映像建立
- VM 可能因無可用 boot source 進行複製而無法啟動
## Diagnosis
1. 檢查是否有預設 StorageClass:
$ kubectl get sc -o jsonpath='{.items[?(.metadata.annotations
.storageclass\.kubernetes\.io\/is-default-class=="true")]
.metadata.name}'
2. 列出未更新的 DataImportCron:
$ kubectl get dataimportcron -A \
-o jsonpath='{range .items[*]}{.status.conditions
[?(@.type=="UpToDate")].status}{"\t"}{.metadata.namespace}
{"/"}{.metadata.name}{"\n"}{end}' | grep False
## Mitigation
設定預設 StorageClass 或在 DataImportCron spec 中指定 StorageClass。
若為離線環境,停用 enableCommonBootImageImport feature gate。來源
monitoring/docs/runbooks/CDIDataImportCronOutdated.md
範例 Runbook 3:SSPCommonTemplatesModificationReverted
# SSPCommonTemplatesModificationReverted
## Meaning
SSP Operator 在 reconciliation 過程中回復了 common template 的變更。
SSP Operator 部署並 reconcile common templates 與 Template Validator,
若有人修改了 common template,SSP 會將變更回復。
## Impact
對 common templates 的變更會被覆寫。
## Diagnosis
1. 設定 NAMESPACE 環境變數:
$ export NAMESPACE="$(kubectl get deployment -A \
| grep ssp-operator | awk '{print $1}')"
2. 檢查 ssp-operator 日誌中被回復的 templates:
$ kubectl -n $NAMESPACE logs --tail=-1 \
-l control-plane=ssp-operator | grep 'common template' -C 3
## Mitigation
確保僅修改 template 的副本,而非 template 本身。來源
monitoring/docs/runbooks/SSPCommonTemplatesModificationReverted.md
Prometheus 指標
docs/metrics.md 彙整了來自 8 個 Operator 的 212 項指標(128 項 Metric + 84 項 Recording Rule),由 tools/metricsdocs 自動生成。
指標來源 Operator
| Operator 短名 | 專案名稱 | Metric 數量 | Recording Rule 數量 |
|---|---|---|---|
| KUBEVIRT | kubevirt | ~100 | ~53 |
| CDI | containerized-data-importer | ~10 | ~6 |
| SSP | ssp-operator | ~5 | ~10 |
| HCO | hyperconverged-cluster-operator | ~8 | ~5 |
| CNAO | cluster-network-addons-operator | ~3 | ~6 |
| HPPO | hostpath-provisioner-operator | ~2 | ~1 |
| HPP | hostpath-provisioner | ~1 | — |
| KMP | kubemacpool | ~2 | — |
來源路徑
monitoring/docs/metrics.md — 由 tools/metricsdocs/metricsdocs.go 自動生成
指標命名前綴規範
根據 monitoring-guidelines.md,所有指標遵循統一的前綴命名:
| 前綴 | 適用範圍 | 範例 |
|---|---|---|
kubevirt_vmi_* | 運行中的 VMI 指標 | kubevirt_vmi_cpu_usage_seconds_total, kubevirt_vmi_memory_available_bytes |
kubevirt_vm_* | VM 層級指標 | kubevirt_vm_info, kubevirt_vm_resource_requests |
kubevirt_hco_* | HCO Operator 指標 | kubevirt_hco_hyperconverged_cr_exists |
kubevirt_cdi_* | Storage/CDI Operator 指標 | kubevirt_cdi_clone_progress_total, kubevirt_cdi_cr_ready |
kubevirt_network_* | 網路 Operator 指標 | kubevirt_cnao_cr_ready |
kubevirt_ssp_* | SSP Operator 指標 | kubevirt_ssp_operator_reconcile_succeeded |
kubevirt_hpp_* | HPP Operator 指標 | kubevirt_hpp_pool_path_shared_with_os |
命名對齊原則
指標命名需與 Kubernetes 內建指標對齊。例如 Kubernetes 有 node_network_receive_packets_total 和 container_network_receive_packets_total,KubeVirt 對應地使用 kubevirt_vmi_network_receive_packets_total。
來源:monitoring/monitoring-guidelines.md
指標類型分布
| 類型 | 數量 | 說明 |
|---|---|---|
| Gauge | 157 | 可升可降的瞬時值(如 kubevirt_vmi_memory_available_bytes) |
| Counter | 47 | 只增不減的累計值(如 kubevirt_vmi_cpu_usage_seconds_total) |
| Histogram | 8 | 分佈直方圖(如 kubevirt_vmi_phase_transition_time_from_creation_seconds) |
代表性指標範例
VM 生命週期:
kubevirt_vmi_phase_transition_time_from_creation_seconds (Histogram)
→ VMI 從建立到各階段(Pending/Scheduling/Running)的延遲分佈
kubevirt_vmi_info (Gauge)
→ VMI 的詳細資訊(namespace, name, phase 等 label)資源用量:
kubevirt_vmi_memory_available_bytes (Gauge) — VM 可用記憶體
kubevirt_vmi_memory_usable_bytes (Gauge) — 可回收記憶體(不含 cache)
kubevirt_vmi_cpu_usage_seconds_total (Counter) — CPU 總使用時間
kubevirt_vmi_filesystem_capacity_bytes (Gauge) — 檔案系統總容量遷移監控:
kubevirt_vmi_migration_data_processed_bytes (Gauge) — 已遷移資料量
kubevirt_vmi_migration_data_remaining_bytes (Gauge) — 剩餘遷移資料量
kubevirt_vmi_migration_dirty_memory_rate_bytes (Gauge) — 記憶體髒頁速率
kubevirt_vmi_migrations_in_running_phase (Gauge) — 正在執行的遷移數網路流量:
kubevirt_vmi_network_receive_bytes_total (Counter)
kubevirt_vmi_network_transmit_bytes_total (Counter)
kubevirt_vmi_network_receive_packets_total (Counter)
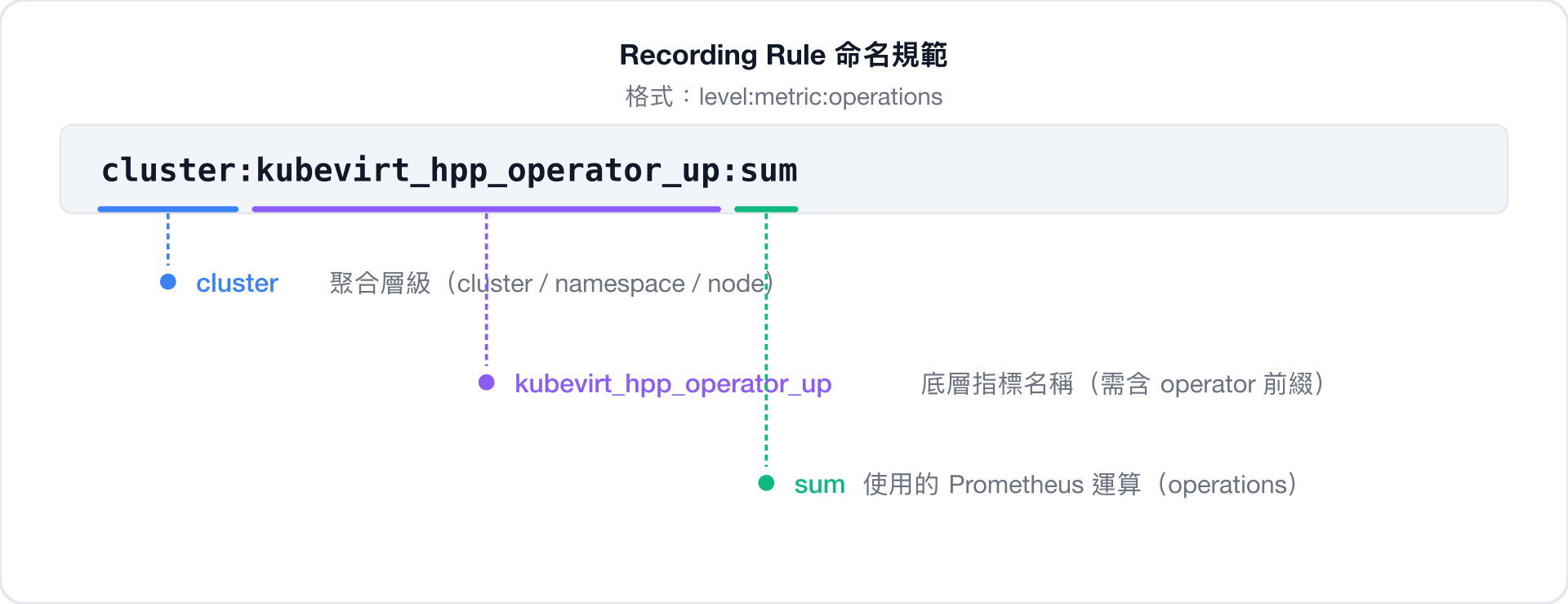
kubevirt_vmi_network_transmit_packets_total (Counter)Recording Rule 命名規範
Recording Rule 使用冒號分隔的三段式命名 level:metric:operations:
Grafana 儀表板
dashboards/ 目錄提供兩組預建儀表板,分別針對 Grafana 原生環境與 OpenShift Console。
kubevirt-control-plane.json
此儀表板包含 6 個分區(Row)、超過 30 個面板(Panel),全方位監控 KubeVirt 控制面板效能。
| 分區 | 面板 | 類型 | 關鍵 PromQL |
|---|---|---|---|
| Virtual Machines | VMI Creation Time | graph | histogram_quantile(0.95, sum(rate(kubevirt_vmi_phase_transition_time_from_creation_seconds_bucket{...}[5m])) by (phase, le)) |
| VMI Start Rate | graph | sum(rate(kubevirt_vmi_phase_transition_time_from_creation_seconds_count{phase="Running"}[5m])) by (instance) | |
| VMI Phase Transition Latency | graph | 6 條查詢分別追蹤 Pending/Scheduling/Scheduled/Running/Succeeded/Failed 的 P95 延遲 | |
| VMI Count (approx.) | graph | 使用 increase() 統計 Failed 與 Running VMI 數量 | |
| KubeVirt API Access | API Server Read/Write Requests Rate | graph | sum(rate(apiserver_request_total{group=~".*kubevirt.*", verb=~"LIST|GET"}[5m])) by (code, group) |
| API Server Read/Write Duration | graph | histogram_quantile(0.90, ...) 計算 P90 延遲 | |
| API Client Rate Limiter Duration | graph | histogram_quantile(0.99, sum(irate(rest_client_rate_limiter_duration_seconds_bucket{...}[5m]))) | |
| KubeVirt Work Queue | Work Queue Add Rate | graph | sum(rate(kubevirt_workqueue_adds_total{...}[1m])) by (instance, name) |
| Work Queue Depth | graph | kubevirt_workqueue_depth{...} | |
| Queue/Work Duration | graph | P99 分位數計算 | |
| Unfinished Work / Retry Rate | graph | kubevirt_workqueue_unfinished_work_seconds, rate(kubevirt_workqueue_retries_total[1m]) | |
| K8s API Access | 非 KubeVirt API 的讀寫速率與延遲 | graph | 使用 pod!~"virt-.*" 排除 KubeVirt 元件 |
| Schedule / Pod Start Latency | graph | histogram_quantile(0.99, ...) | |
| Resource Usage | Memory / CPU / Open Files | graph | process_resident_memory_bytes, rate(process_cpu_seconds_total[5m]) |
| Network / GC Duration / Goroutines / Threads | graph | Go runtime 指標 | |
| Storage Operations | Storage Operation Rate/Error Rate | graph | storage_operation_duration_seconds_count |
| etcd | RPC Rate / DB Size / Wal Fsync / RTT | graph | etcd 底層效能指標 |
來源路徑
monitoring/dashboards/grafana/kubevirt-control-plane.json — 5,195 行 JSON
kubevirt-top-consumers.json
此儀表板專注於 VM 資源消耗排行榜,包含 2 個分區、14 個面板。
| 分區 | 面板 | 類型 | PromQL 查詢 |
|---|---|---|---|
| Top Consumers | Top Consumers of Memory | table | sort_desc(topk(5, sum(avg_over_time(kubevirt_vmi_memory_available_bytes[$__range]) - avg_over_time(kubevirt_vmi_memory_usable_bytes[$__range])) by(name, namespace)))>0 |
| Top Consumers of CPU | table | sort_desc(topk(5, sum(rate(container_cpu_usage_seconds_total{container="compute", pod=~"virt-launcher-.*"}[$__range])) by (namespace, pod)))>0 | |
| Top Consumers of Storage Traffic | table | sum(rate(kubevirt_vmi_storage_read_traffic_bytes_total[...]) + rate(kubevirt_vmi_storage_write_traffic_bytes_total[...])) | |
| Top Consumers of Storage IOPS | table | kubevirt_vmi_storage_iops_read_total + kubevirt_vmi_storage_iops_write_total | |
| Top Consumers of Network Traffic | table | kubevirt_vmi_network_receive_bytes_total + kubevirt_vmi_network_transmit_bytes_total | |
| Top Consumers of vCPU Wait | table | kubevirt_vmi_vcpu_wait_seconds_total | |
| Top Consumers of Memory Swap Traffic | table | kubevirt_vmi_memory_swap_in_traffic_bytes + kubevirt_vmi_memory_swap_out_traffic_bytes | |
| Top Consumers Over Time | Memory/CPU/Storage/Network/vCPU/Swap 趨勢圖 | graph | 與上方相同指標的 irate() 時序版本 |
來源路徑
monitoring/dashboards/openshift/kubevirt-top-consumers.json — 1,955 行 JSON
指標 Linter 工具
KubeVirt Monitoring 提供兩層 Linter,確保所有 Operator 的監控程式碼遵循一致的品質標準。
第一層:Monitoring Linter(Go 靜態分析器)
位於 monitoringlinter/ 的 Go analysis.Analyzer,以 AST 分析方式強制執行監控程式碼的存放位置規範。
// monitoring/monitoringlinter/analyzer.go
func NewAnalyzer() *analysis.Analyzer {
return &analysis.Analyzer{
Name: "monitoringlinter",
Doc: "Ensures that in Kubernetes operators projects, " +
"monitoring related practices are implemented " +
"within pkg/monitoring directory, " +
"using operator-observability packages.",
Run: run,
}
}核心規則:
| 規則 | 說明 |
|---|---|
禁止在 pkg/monitoring/ 以外呼叫 operatormetrics.RegisterMetrics() | 指標註冊必須集中在監控目錄 |
禁止在 pkg/monitoring/ 以外呼叫 operatorrules.RegisterAlerts() | 告警規則註冊必須集中在監控目錄 |
全面禁止直接使用 prometheus.Register() / prometheus.MustRegister() | 即使在 pkg/monitoring/ 內也不允許直接用 Prometheus SDK 註冊 |
檢測流程:
- 掃描每個 Go 檔案的 import 宣告,辨識是否引入了 Prometheus 或 operator-observability 套件
- 透過 AST 走訪找出
Call Expression(函數呼叫) - 比對呼叫的套件名稱與方法名稱(支援自訂 alias import)
- 檢查檔案路徑是否在
pkg/monitoring目錄中
來源
monitoring/monitoringlinter/analyzer.go
第二層:Prometheus Metrics Linter(自訂命名規則)
位於 test/metrics/prom-metrics-linter/,負責驗證指標名稱與 Recording Rule 的命名正確性。
程式架構
test/metrics/prom-metrics-linter/
├── custom_linter_rules.go ← 入口:解析 JSON 輸入、執行 promlint + 自訂驗證
├── metric_name_linter.go ← 核心驗證邏輯:指標前綴、Recording Rule 結構
└── allowlist.json ← 豁免清單:各 Operator 的歷史遺留指標指標名稱驗證(CustomMetricsValidation)
// monitoring/test/metrics/prom-metrics-linter/metric_name_linter.go
func CustomMetricsValidation(problems []promlint.Problem, mf *dto.MetricFamily,
operatorName, subOperatorName string) []promlint.Problem {
// 規則 1:指標名稱必須以 operatorName 開頭(如 "kubevirt_")
// 規則 2:若 subOperatorName 不同,需以 "operatorName_subOperatorName_" 開頭
// 規則 3:Counter 類型允許 "_total" 或 "_timestamp_seconds" 後綴
}Recording Rule 驗證(CustomRecordingRuleValidation)
四項驗證規則依序執行:
| 驗證函數 | 規則說明 | 範例 |
|---|---|---|
validateRecordingRuleNameStructure | 名稱必須為 level:metric:operations 三段式 | ✅ cluster:kubevirt_vmi_phase_count:sum |
validateRecordingRuleMetricPrefix | metric 段必須以 operator_suboperator 開頭 | ✅ cluster:kubevirt_vmi_*:sum |
validateRecordingRuleOpsSuffix | operations 段必須包含 expr 中偵測到的運算 | 偵測到 sum → 末尾需含 sum |
validateRecordingRuleNoDuplicateOps | operations 段不得有重複 token | ❌ min_min → 應為 min |
可偵測的 Prometheus 運算
// monitoring/test/metrics/prom-metrics-linter/metric_name_linter.go
// 聚合運算(14 種)
promAggOps = []string{
"sum", "avg", "min", "max", "count", "quantile",
"stddev", "stdvar", "group", "count_values",
"limitk", "limit_ratio", "topk", "bottomk",
}
// 時間運算(14 種)
promTimeOps = []string{
"rate", "irate", "increase", "delta", "idelta", "deriv",
"avg_over_time", "min_over_time", "max_over_time",
"sum_over_time", "count_over_time", "quantile_over_time",
"stddev_over_time", "stdvar_over_time",
}Allowlist 豁免機制
allowlist.json 透過 Go //go:embed 嵌入二進位檔中,為各 Operator 的歷史遺留指標提供豁免:
// monitoring/test/metrics/prom-metrics-linter/allowlist.json(節錄)
{
"operators": {
"kubevirt": [
"kubevirt_allocatable_nodes",
"kubevirt_virt_api_up",
"kubevirt_virt_controller_ready",
"kubevirt_vmi_phase_count",
"kubevirt_number_of_vms"
// ... 共 22 項
],
"hco": [
"cnv_abnormal",
"kubevirt_hyperconverged_operator_health_status",
"cluster:vmi_request_cpu_cores:sum"
],
"cdi": [
"kubevirt_cdi_clone_pods_high_restart",
"kubevirt_cdi_operator_up"
// ... 共 4 項
],
"ssp": [
"cnv:vmi_status_running:count",
"kubevirt_ssp_operator_up"
// ... 共 6 項
]
}
}來源
monitoring/test/metrics/prom-metrics-linter/custom_linter_rules.go、metric_name_linter.go、allowlist.json
指標文件生成器
tools/metricsdocs/ 是一套 Go 工具,負責從 9 個 Operator 的 Git 倉庫拉取指標文件,合併生成統一的 docs/metrics.md。
架構總覽
tools/metricsdocs/
├── metricsdocs.go ← 主程式:參數解析、checkout、文件解析、模板渲染
├── types.go ← 資料結構:projectInfo、Metric、TemplateOperator
├── git.go ← Git 操作:clone / pull / checkout branch
├── metrics.tmpl ← Go template:最終 metrics.md 的輸出模板
├── config ← 各 Operator 版本設定檔
└── go.mod ← 依賴:github.com/joho/godotenv支援的 9 個 Operator
// monitoring/tools/metricsdocs/types.go
var projectsInfo = []*projectInfo{
{"KUBEVIRT", "kubevirt", "kubevirt", "docs/observability/metrics.md"},
{"CDI", "containerized-data-importer", "kubevirt", "doc/metrics.md"},
{"NETWORK_ADDONS", "cluster-network-addons-operator", "kubevirt", "docs/metrics.md"},
{"SSP", "ssp-operator", "kubevirt", "docs/metrics.md"},
{"NMO", "node-maintenance-operator", "kubevirt", "docs/metrics.md"},
{"HPPO", "hostpath-provisioner-operator", "kubevirt", "docs/metrics.md"},
{"HPP", "hostpath-provisioner", "kubevirt", "docs/metrics.md"},
{"HCO", "hyperconverged-cluster-operator", "kubevirt", "docs/metrics.md"},
{"KMP", "kubemacpool", "k8snetworkplumbingwg", "doc/metrics.md"},
}版本設定檔
# monitoring/tools/metricsdocs/config
KUBEVIRT_VERSION="main"
CDI_VERSION="main"
NETWORK_ADDONS_VERSION="main"
SSP_VERSION="main"
NMO_VERSION="master" # 注意:NMO 使用 master 分支
HPPO_VERSION="main"
HPP_VERSION="main"
HCO_VERSION="main"
KMP_VERSION="main"生成流程
1. 解析參數 parseArguments()
│ ├── --config-file: 版本設定檔路徑
│ └── --cache-dir: Git 快取目錄
│
2. Checkout 各專案 checkoutProjects()
│ ├── gitCloneUpstream() 或 gitUpdateFromUpstream()
│ └── gitSwitchToBranch(version)
│
3. 解析指標文件 parseMetrics()
│ ├── 讀取各專案的 metrics.md
│ └── parseMetricsDoc() 解析 Markdown 表格
│ → 提取 Name | Kind | Type | Description
│
4. 排序指標 sortMetrics()
│ ├── kubevirt 的指標排在最前面
│ ├── 同 Operator 內 Metric 排在 Recording Rule 之前
│ └── 同類型按名稱字母排序
│
5. 渲染模板 writeMetrics()
└── metricsTmpl.Execute() 生成 docs/metrics.md模板與格式化函數
// monitoring/tools/metricsdocs/metricsdocs.go
metricsTmpl = template.New("metrics").Funcs(template.FuncMap{
"escapePipe": func(s string) string {
return strings.ReplaceAll(s, "|", "\\|") // 跳脫 Markdown 表格分隔符
},
"normalizeDescription": func(s string) string {
// 跳脫 pipe、移除換行、去除前後空白
},
"codeSpan": func(s string) string {
return "`" + s + "`" // 包裹為行內程式碼
},
})輸出模板結構:
// monitoring/tools/metricsdocs/metrics.tmpl
# KubeVirt components metrics
## Operator Repositories
| Operator Name |
|---------------|
{{range .Operators}}| {{.Link}} |
{{end}}
## Metrics
| Operator Name | Name | Kind | Type | Description |
|----------|------|------|------|-------------|
{{range .Metrics}}| {{.Operator}} | {{.Name}} | {{.Kind}} | {{.Type}} | {{.Description}} |
{{end}}來源路徑
monitoring/tools/metricsdocs/metricsdocs.go、types.go、git.go、metrics.tmpl、config