Node Maintenance Operator — 系統架構
架構概覽
Node Maintenance Operator 採用單一控制器架構:一個 binary(main.go)、一個 reconciler(NodeMaintenanceReconciler)、一個 CRD(NodeMaintenance)。

設計哲學
單一 CRD、單一控制器,職責明確。使用者只需建立或刪除一個 NodeMaintenance CR,Operator 即自動完成節點的封鎖與驅逐(或恢復)。
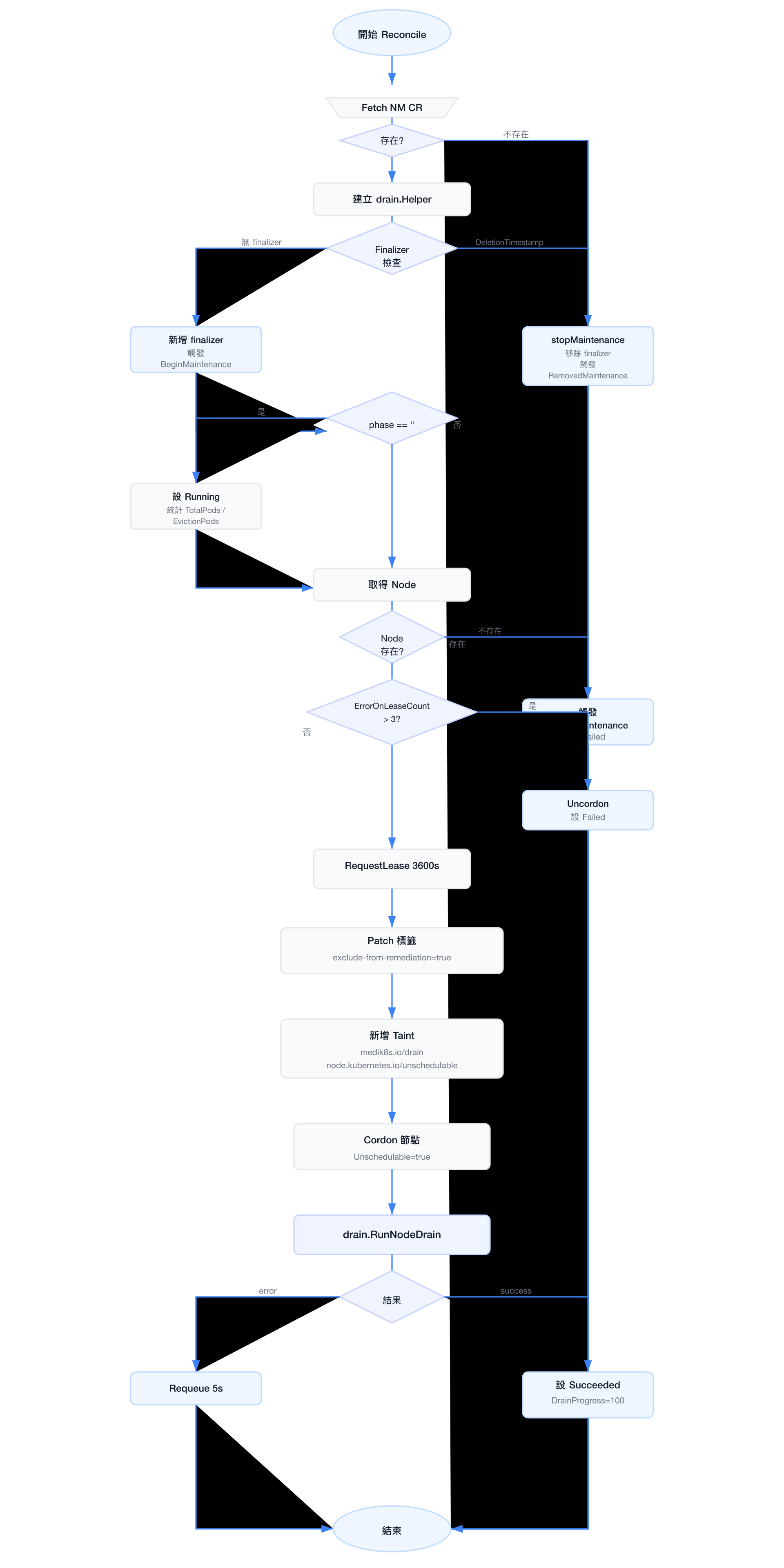
Reconcile 流程(完整步驟)
以下為每次 reconcile 執行的完整步驟:
- Fetch NodeMaintenance CR — 若不存在則直接結束(已刪除且 finalizer 已清除)
- 建立 drain.Helper — 依設定初始化 drainer(Force、DeleteEmptyDirData、IgnoreAllDaemonSets 等)
- Finalizer 處理:
- 若 CR 尚無 finalizer → 新增
foregroundDeleteNodeMaintenance,並觸發BeginMaintenance事件 - 若
DeletionTimestamp已設定 → 執行stopMaintenance(uncordon + 移除 taint + 釋放 lease),移除 finalizer,觸發RemovedMaintenance事件
- 若 CR 尚無 finalizer → 新增
- 初始化 Status — 若
phase == ""→ 設為Running,統計TotalPods與EvictionPods - 取得節點 — 依
spec.nodeName查詢 Node;若找不到 → 觸發FailedMaintenance事件,設 phase =Failed - Lease 檢查 — 若
ErrorOnLeaseCount > 3→ uncordon 節點並設Failed;否則呼叫RequestLease(node, 3600s) - Patch 節點標籤 — 加入
medik8s.io/exclude-from-remediation=true - 新增 Taint — 加入
medik8s.io/drain:NoSchedule與node.kubernetes.io/unschedulable:NoSchedule - Cordon 節點 — 設定
node.Spec.Unschedulable = true - drain.RunNodeDrain — 若失敗:requeue 5 秒;若成功:設 phase =
Succeeded,DrainProgress = 100
狀態機
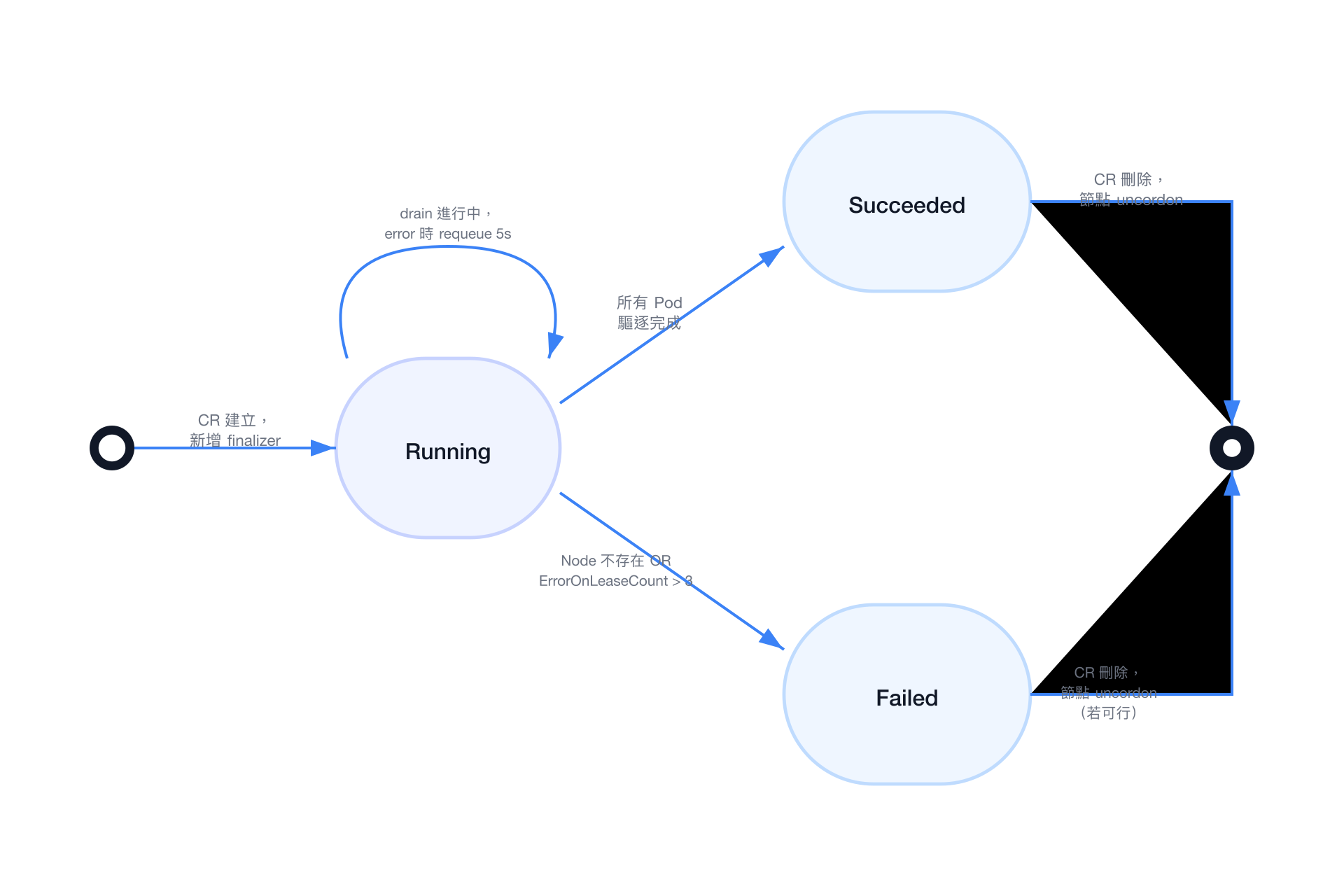
Failed 狀態說明
進入 Failed 狀態後,Operator 不再自動重試。需由使用者手動刪除 CR,Operator 將在刪除流程中嘗試 uncordon 節點。
主要元件表格
| 元件 | 位置 | 職責 |
|---|---|---|
NodeMaintenanceReconciler | controllers/nodemaintenance_controller.go | 主控制器,協調所有維護操作 |
LeaseManager | vendor/github.com/medik8s/common/pkg/lease | 分散式 lease 協調 |
drain.Helper | k8s.io/kubectl/pkg/drain | Pod 驅逐與節點排空 |
NodeMaintenanceValidator | api/v1beta1/nodemaintenance_webhook.go | Admission webhook 驗證 |
EventRecorder | pkg/utils/events.go | Kubernetes 事件記錄 |
Drainer 設定
go
// 檔案: controllers/nodemaintenance_controller.go
drainer := &drain.Helper{
Client: r.drainerClient,
Force: true,
DeleteEmptyDirData: true,
IgnoreAllDaemonSets: true,
GracePeriodSeconds: -1,
Timeout: 30 * time.Second,
Out: writer{klog.Info},
ErrOut: writer{klog.Error},
Ctx: ctx,
}| 參數 | 值 | 原因 |
|---|---|---|
Force | true | 驅逐無 controller 的 Pod(VirtualMachineInstance) |
DeleteEmptyDirData | true | 刪除含 emptyDir 的 Pod(VM 暫存資料) |
IgnoreAllDaemonSets | true | 跳過 DaemonSet Pod(virt-handler 等) |
GracePeriodSeconds | -1 | 使用 Pod 預設 grace period |
Timeout | 30秒 | 等待所有 Pod 終止的最大時間 |
Force 模式注意事項
Force: true 會驅逐沒有 owner reference 或 owner 不是 ReplicaSet/DaemonSet 的 Pod,這是為了正確處理 KubeVirt 的 VirtualMachineInstance Pod。使用時請確認叢集上不存在其他需要保護的孤立 Pod。
啟動設定(main.go)
go
// 檔案: main.go
flag.StringVar(&metricsAddr, "--metrics-bind-address", ":8080", "Metrics 端點位址")
flag.StringVar(&probeAddr, "--health-probe-bind-address", ":8081", "Health probe 端點位址")
flag.BoolVar(&enableLeaderElect, "--leader-elect", false, "啟用 Leader Election")
flag.BoolVar(&enableHTTP2, "--enable-http2", false, "啟用 HTTP/2(預設停用以緩解 CVE)")| Flag | 預設值 | 說明 |
|---|---|---|
--metrics-bind-address | :8080 | Prometheus metrics 端點 |
--health-probe-bind-address | :8081 | Health / Ready 探針端點 |
--leader-elect | false | 啟用 Leader Election |
--enable-http2 | false | 啟用 HTTP/2(預設關閉以緩解 CVE) |
go
// 檔案: main.go
const (
WebhookCertDir = "/apiserver.local.config/certificates/"
WebhookCertName = "apiserver.crt"
WebhookKeyName = "apiserver.key"
)
LeaderElectionID: "135b1886.medik8s.io"HTTP/2 預設停用
--enable-http2 預設為 false,目的是緩解已知的 HTTP/2 相關 CVE(如 CVE-2023-44487 Rapid Reset Attack)。Webhook 與 Metrics 伺服器強制使用 HTTP/1.1,除非明確啟用。