Node Maintenance Operator — 節點排空工作流程
概述
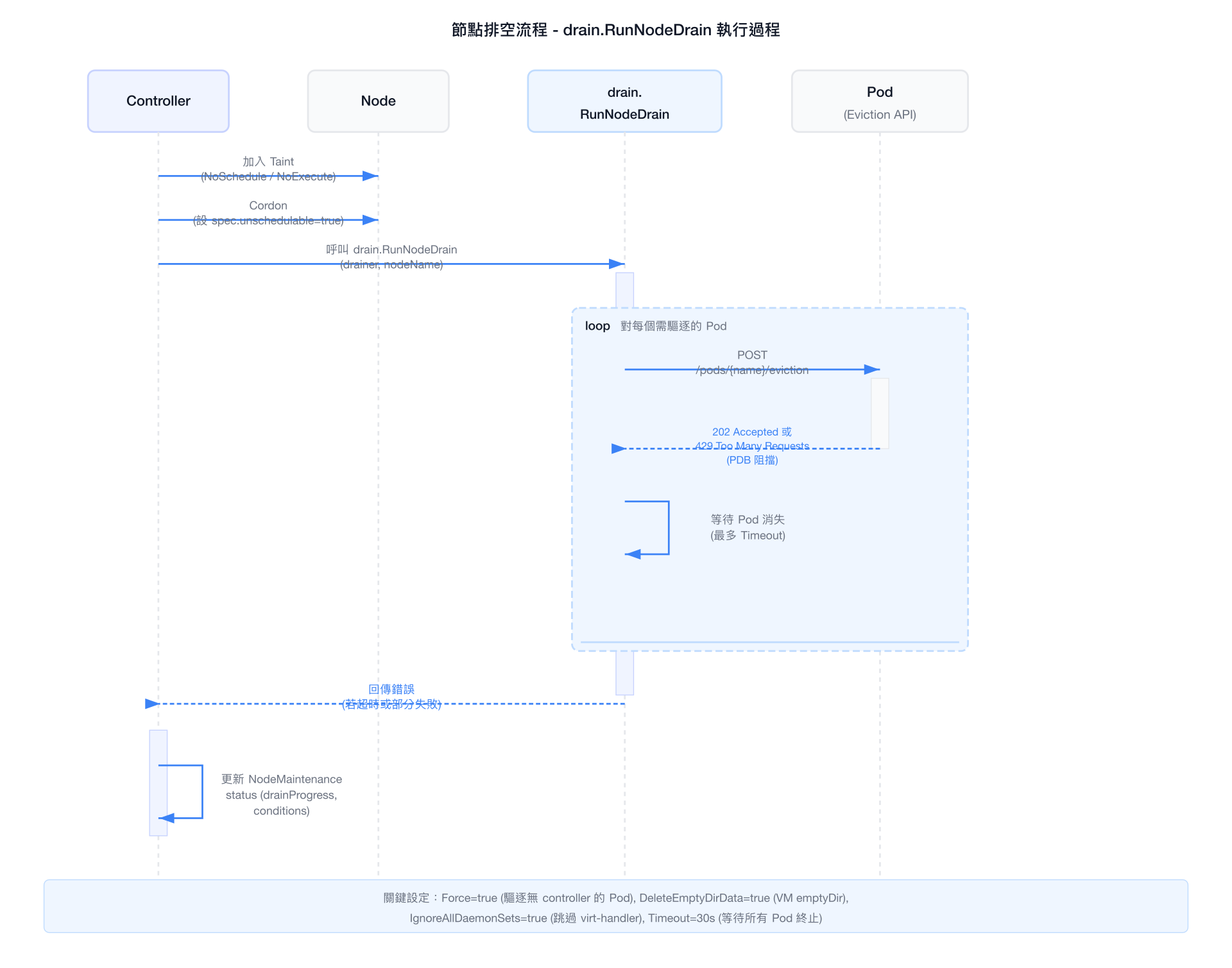
NMO 使用 k8s.io/kubectl/pkg/drain 套件模擬 kubectl drain 行為,讓節點進入維護模式時能安全地將工作負載遷移至其他節點。排空流程分為三個獨立操作:
- 加 Taint — 標記節點不可排程新工作負載
- Cordon — 封鎖節點,防止新 Pod 被排程上來
- 驅逐 Pod — 透過 Eviction API 依序驅逐現有 Pod
這三個步驟確保排空過程安全、可觀測,且與 PodDisruptionBudget 相容。
排空觸發流程
drain.Helper 設定詳解
NMO 在每次 reconcile 時建立 drain.Helper,並依 KubeVirt 環境特性設定各欄位:
// 檔案: controllers/nodemaintenance_controller.go
drainer := &drain.Helper{
Ctx: ctx,
Client: r.drainer.Client,
Force: true, // 驅逐無 controller 管理的 Pod
DeleteEmptyDirData: true, // 允許刪除有 emptyDir 的 Pod
IgnoreAllDaemonSets: true, // 忽略所有 DaemonSet Pod
GracePeriodSeconds: -1, // 使用 Pod 自訂的 grace period
Timeout: 30 * time.Second,
Out: writer,
ErrOut: writer,
}| 欄位 | 值 | 說明 |
|---|---|---|
Force | true | 強制驅逐無 owner reference 的 Pod(如 standalone VirtualMachineInstance pods)。若設為 false,這類 Pod 會阻擋排空。 |
DeleteEmptyDirData | true | 允許驅逐使用 emptyDir volume 的 Pod,這類資料為暫存性,驅逐後會消失。 |
IgnoreAllDaemonSets | true | 跳過所有 DaemonSet Pod(如 virt-handler、CNI 插件),因為它們無法被排程至其他節點,且節點上線後會自動恢復。 |
GracePeriodSeconds | -1 | 採用每個 Pod 自身設定的 terminationGracePeriodSeconds,不由 drain 覆寫,確保 VM 等工作負載有足夠時間完成遷移。 |
Timeout | 30s | 每次 drain 嘗試的超時上限;若未完成,controller 會重新排隊並在 5 秒後重試。 |
Force=true 的風險
Force: true 會驅逐沒有 controller(Deployment、ReplicaSet 等)管理的 Pod。這些 Pod 被刪除後不會自動重建,請確認節點上不存在必須保留的 standalone Pod。
IgnoreAllDaemonSets 與 virt-handler
virt-handler 是 KubeVirt 的 DaemonSet Pod,負責管理節點上的 VM。設定 IgnoreAllDaemonSets: true 可確保排空時不會嘗試驅逐它,避免因驅逐失敗而卡住整個排空流程。
Pod 驅逐 vs 刪除
kubectl drain(以及 NMO)支援兩種移除 Pod 的策略:
Eviction API(預設)
- 路徑:
POST /api/v1/namespaces/{ns}/pods/{name}/eviction - 尊重 PodDisruptionBudget:若 PDB 不允許此時驅逐,API 回傳
429 Too Many Requests,drain 會重試 - 支援 graceful termination,Pod 收到
SIGTERM後有時間完成清理
Force Delete
- 直接刪除 Pod 物件,不等待 graceful shutdown
- 僅在 eviction 超時或 Pod 沒有 owner reference 且
Force=true時使用
NMO 預設走 Eviction API,因此需要以下 RBAC 權限:
# 檔案: config/rbac/role.yaml
- apiGroups: [""]
resources: ["pods/eviction"]
verbs: ["create"]PodDisruptionBudget 尊重
NMO 在排空時會讀取叢集中的 PDB,並透過 Eviction API 自動尊重其設定。
# 檔案: config/rbac/role.yaml
- apiGroups: ["policy"]
resources: ["poddisruptionbudgets"]
verbs: ["get", "list", "watch"]若 PDB 阻擋了某個 Pod 的驅逐(例如 minAvailable 限制),drain 會:
- 收到
429 Too Many Requests回應 - 等待並重試
- 若在
Timeout(30s)內仍無法驅逐,回傳錯誤 - Controller 將在
waitDurationOnDrainError(5s)後重新排隊,繼續嘗試
TIP
PDB 保護機制確保高可用性工作負載(如多副本 Deployment)在節點維護期間仍維持最低可用副本數。
DaemonSet 處理
設定 IgnoreAllDaemonSets: true 後,drain 會完全跳過 DaemonSet 管理的 Pod,包含:
virt-handler(KubeVirt VM 管理)- CNI 插件(如 Multus、Calico node agent)
- 監控 agent(如 node-exporter、Fluentd)
- 儲存 agent(如 Ceph OSD、Longhorn)
這些 Pod 被設計為「每個節點必須有一個」,無法排程至其他節點。當維護結束、節點重新加入叢集後,DaemonSet controller 會自動重新在該節點建立對應的 Pod。
WARNING
跳過 DaemonSet Pod 意味著節點排空期間,這些 agent 仍在運行。若需要完全隔離節點上的所有工作負載,需要額外手動處理。
排空進度計算
NMO 透過 drainProgress 欄位(0–100)向使用者回報排空進度:
// 檔案: controllers/nodemaintenance_controller.go
DrainProgress = (EvictionPods - len(PendingPods)) * 100 / EvictionPodsEvictionPods:排空開始時需驅逐的 Pod 總數(快照)PendingPods:目前仍在等待驅逐的 Pod 數量- 進度在每次
onReconcileErrorWithRequeue()呼叫時更新,即每次重試時刷新
範例:若共有 10 個 Pod 需驅逐,目前剩 4 個,則 drainProgress = (10-4)*100/10 = 60。
錯誤重試策略
| 錯誤類型 | 重試行為 |
|---|---|
| drain 未完成(Pod 仍存在) | 固定等待 5 秒後重新排隊 |
| 節點不存在 | 不重試,設狀態為 Failed |
| Lease 取得失敗超過 3 次 | 不重試,先 uncordon 節點後設狀態為 Failed |
| 其他 API 錯誤 | 指數退避(由 controller-runtime 預設處理) |
等待時間由以下常數定義:
// 檔案: controllers/nodemaintenance_controller.go
waitDurationOnDrainError = 5 * time.Second固定 5 秒等待(而非指數退避)的設計考量:排空是一個持續性操作,過長的等待會延誤維護視窗,過短則會對 API server 造成不必要的壓力。
維護完成後的恢復流程
當 NodeMaintenance CR 被刪除時,controller 呼叫 stopNodeMaintenanceImp() 執行以下步驟:
移除 exclude-from-remediation label
- 讓節點重新納入 remediation 機制的管轄範圍
移除 Taint
go// 檔案: controllers/nodemaintenance_controller.go AddOrRemoveTaint(r.drainer.Client, node, false) // add=false 表示移除Uncordon 節點
go// 檔案: controllers/nodemaintenance_controller.go drain.RunCordonOrUncordon(r.drainer, node, false) // false = uncordon釋放 Lease
go// 檔案: controllers/nodemaintenance_controller.go InvalidateLease(ctx, r.Client, nodeName)
TIP
恢復流程是自動執行的——只需刪除 NodeMaintenance CR,NMO 便會還原節點至正常狀態,無需手動 uncordon。
與 kubectl drain 的差異
| 面向 | kubectl drain | NMO |
|---|---|---|
| 觸發方式 | 手動指令 | CR 驅動(宣告式) |
| 重試機制 | 不自動重試,需手動重新執行 | 自動重試,間隔 5 秒 |
| 狀態追蹤 | 無持久化狀態 | drainProgress 0–100,寫入 CR status |
| 並發保護 | 無 | Lease 機制防止多 controller 同時排空同一節點 |
| 恢復流程 | 需手動執行 kubectl uncordon | 刪除 CR 即自動 uncordon |
| 可觀測性 | 僅終端輸出 | Kubernetes Events + CR conditions |
| PDB 處理 | 尊重(可用 --disable-eviction 跳過) | 尊重,無法跳過 |
相關章節
- 架構總覽 — NMO 整體元件設計與 controller 架構
- Taint 與 Cordon 機制 — 排空前置步驟的詳細說明
- Lease 協調機制 — 防止並發排空的 Lease 實作
- 疑難排解與除錯 — 常見排空失敗情境與解決方式