設計動機與存在價值
本章導讀
本章從「為什麼需要 NMO」出發,深入分析 Kubernetes 內建節點管理機制的侷限,以及 NMO 在 KubeVirt、medik8s 生態中真正解決的三個核心問題:VMI 特殊排空需求、Lease 協調保護、與自動修復系統的共存。
相關章節
- 系統架構 — Reconcile 流程與狀態機
- 節點排空工作流程 — drain 的技術實作
- Lease 分散式協調 — 防止多節點同時維護
- Taint 管理與 Cordoning — 封鎖節點機制
1. 計畫性維護 vs 意外故障 — 兩件完全不同的事
理解 NMO 存在意義,最重要的第一步是釐清兩種情境的根本差異:
| 情境 | 觸發方式 | 目標 | K8s 內建工具 |
|---|---|---|---|
| 意外故障(Reactive) | 硬體壞掉、網路斷線、OOM | 盡快把 Pod 搬走、讓服務恢復 | node not ready 自動驅逐 |
| 計畫性維護(Proactive) | 核心更新、硬體更換、安全補丁 | 優雅排空、通知系統、安全施工後恢復 | ❌ 沒有原生支援 |
K8s 的 node not ready 機制是為了意外故障設計的,整個流程本質上是「發現節點死了,想辦法補救」:
節點突然失聯
→ kubelet 停止回報心跳
→ ~40 秒後 NodeController 標記 NotReady
→ 再等 5 分鐘(node-monitor-grace-period)才開始驅逐
→ Pod 進入 Terminating — 但節點已死,preStop hook 無法執行
→ Pod 可能永久卡在 Terminating,需要人工 kubectl delete pod --force這整個流程是被動、慢速、不優雅的,完全不適用於計畫性維護場景。
2. kubectl drain 也不夠用?
多數工程師第一個想到的替代方案是 kubectl drain。確實,kubectl drain 在技術上做了正確的事:先 cordon(禁止新排程),再逐一驅逐 Pod。但在生產環境中,它有幾個根本性問題:
2.1 不宣告式、不 GitOps 友善
kubectl drain 是命令式操作:
# 需要有人手動執行,執行完就沒有紀錄了
kubectl drain node01 --ignore-daemonsets --delete-emptydir-data- 沒有 YAML 可以 commit 到 Git
- 沒有 audit trail(誰在何時維護了哪個節點)
- 自動化困難(CI/CD pipeline 中需要額外邏輯處理失敗重試)
NMO 的做法:
# 這個 CR 存在於 etcd,可以被 kubectl get/describe,可以 commit 到 Git
apiVersion: nodemaintenance.medik8s.io/v1beta1
kind: NodeMaintenance
metadata:
name: maintain-node01
spec:
nodeName: node01
reason: "Linux kernel security patch CVE-2024-XXXX"2.2 在 KubeVirt 環境下預設會失敗
這是最關鍵的技術差異。從 NMO 原始碼 controllers/nodemaintenance_controller.go 可以看到,NMO 建立 Drainer 時設了三個 kubectl drain 預設不會設的 flag:
// 問題 1:VMI Pod 沒有 ReplicaSet owner
// 標準 drain 看到「孤兒 Pod」會報錯並停下來
// 因為它無法保證這個 Pod 被刪除後會在別處重建
drainer.Force = true
// 問題 2:VMI Pod 使用 emptyDir volumes
// 標準 drain 看到 emptyDir 會警告:「資料會遺失」並停下來
// 但 VMI 的 emptyDir 是暫存的執行環境(非持久資料),可以安全刪除
drainer.DeleteEmptyDirData = true
// 問題 3:每個跑 VM 的節點都有 virt-handler DaemonSet Pod
// 標準 drain 遇到 DaemonSet Pod 會卡住(因為刪了又會被重建)
drainer.IgnoreAllDaemonSets = true沒有這三個 flag,在 KubeVirt 叢集上直接執行 kubectl drain 的結果是:
error: cannot delete Pods not managed by ReplicationController,
ReplicaSet, Job, DaemonSet or StatefulSet (use --force to override)2.3 沒有進度可視化
kubectl drain 只有 terminal 輸出,沒有機器可讀的狀態。NMO 提供詳細的 status:
status:
phase: Running # Running | Succeeded | Failed
drainProgress: 67 # 百分比進度
evictionPods: 12 # 需要驅逐的 Pod 總數
pendingPods: # 還沒驅逐完的 Pod 清單
- kubevirt/virt-launcher-vm-web-01-xxxxx
- default/nginx-deployment-7d6f4b9c-abcde
totalPods: 18
lastError: ""
lastUpdate: "2024-04-09T15:00:00Z"這讓 Grafana dashboard、Prometheus alert、自動化腳本都能即時感知維護進度。
3. NMO 解決的三個核心問題
3.1 VMI 特殊排空 — KubeVirt 的原生夥伴
如上節所述,NMO 對 VMI Pod 的排空行為做了專屬調整。更重要的是,NMO 還需要與 KubeVirt 的 EvictionStrategy 配合:
維護流程(有 KubeVirt):
NMO cordon node
→ virt-handler 偵測到節點 taint(kubevirt.io/drain: NoSchedule)
→ 觸發 VMI live migration(如果 EvictionStrategy: LiveMigrate)
→ VM 無中斷遷移到其他節點
→ NMO 繼續驅逐其他非 VM 的 Pod
→ 節點清空完畢,維護開始相比之下,純 kubectl drain + NodeNotReady 流程會導致 VM 直接關機(斷線),而不是平滑遷移。
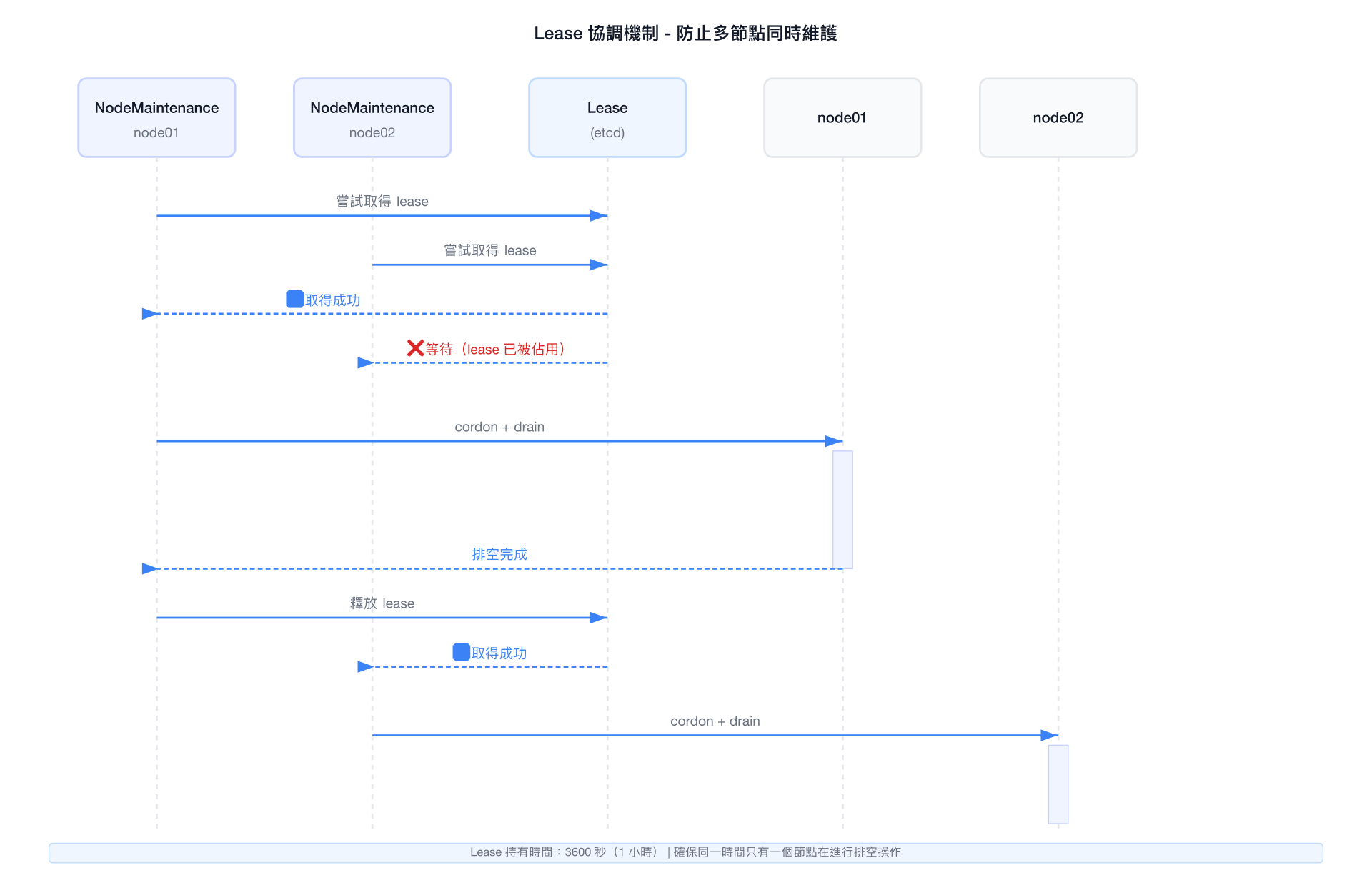
3.2 Lease 協調 — 保護叢集 Quorum
NMO 使用 coordination.k8s.io/leases 實作分散式協調。當多個 NodeMaintenance CR 同時存在時,NMO 確保只有一個節點在進行真正的排空操作:
Lease 持有時間:3600 秒(1 小時)
情境:3 個工程師同時建立 NodeMaintenance CR 給 3 個節點
→ node01 搶到 lease → 開始排空
→ node02 等待 lease → 排隊
→ node03 等待 lease → 排隊
→ node01 完成 → 釋放 lease → node02 取得 lease → 開始排空為什麼這很重要?想像一個 3 master 節點的叢集,如果同時有 2 個 master 進入維護,etcd quorum(需要至少 2/3 節點在線)就會崩潰,整個叢集失去控制平面。
沒有 Lease 協調的純 kubectl drain,完全靠人工協調,非常容易出錯。
3.3 與 Remediation 系統共存 — 防止誤觸自動修復
這是最容易被忽略的設計考量。medik8s 生態包含多個 operator:
| Operator | 職責 |
|---|---|
| NMO | 計畫性維護 |
| Self Node Remediation (SNR) | 節點硬體異常時自動重啟 |
| Node Health Check (NHC) | 監控節點健康、觸發修復 |
| Machine Deletion Remediation | 刪除並重建故障節點 |
問題在於:當 NMO 把節點 cordon + drain 時,節點看起來「不健康」——SNR 或 NHC 可能誤判這是硬體故障,嘗試對這個節點進行 fence(強制重啟) 或 刪除重建,直接中斷正在進行的維護作業,甚至造成資料遺失。
NMO 的解法是在維護開始時加上 label:
// controllers/nodemaintenance_controller.go
func addExcludeRemediationLabel(ctx context.Context, node *corev1.Node, ...) error {
node.Labels[commonLabels.ExcludeFromRemediation] = "true"
// → remediation.medik8s.io/exclude-from-remediation: "true"
}SNR、NHC 等 operator 看到這個 label 就會跳過該節點,不觸發修復流程。維護結束後,NMO 自動移除這個 label,節點重新納入健康監控。
維護期間節點 Labels:
node.kubernetes.io/unschedulable: "true" ← cordon
medik8s.io/drain: NoSchedule ← KubeVirt migration taint
remediation.medik8s.io/exclude-from-remediation: "true" ← 防止 SNR/NHC 誤動作4. 功能對比總表
| 能力 | K8s NodeNotReady | kubectl drain | NMO |
|---|---|---|---|
| 計畫性維護 | ❌ | ⚠️ 需手動 | ✅ |
| 宣告式 / GitOps | ❌ | ❌ | ✅ |
| Audit trail(CR 紀錄) | ❌ | ❌ | ✅ |
| 維護進度可視化 | ❌ | ❌ | ✅ drainProgress |
| KubeVirt VMI 支援 | ❌ | ❌ 需加 flag | ✅ 自動 |
| VM Live Migration 整合 | ❌ | ❌ | ✅ |
| 防止多節點同時維護 | ❌ | ❌ | ✅ Lease |
| 與 SNR/NHC 共存 | ❌ | ❌ | ✅ ExcludeFromRemediation |
| 自動 uncordon(維護後) | ❌ | ❌ 需手動 | ✅ 刪 CR 即恢復 |
| 維護逾時保護 | ❌ | ❌ | ✅ DrainerTimeout |
5. 一句話總結
K8s
node not ready是消防系統(被動滅火),kubectl drain是手動工具(需要人在場),NMO 是施工管制系統(計畫性申請、自動協調、通知相關系統、安全完工後自動恢復)。
三者解決的是本質上不同的問題,在跑 KubeVirt 的生產叢集中,三者同時存在、各司其職,才能達到真正的高可用維護體驗。