Live Migration — 不中斷服務的 VM 遷移
Live Migration 是 KubeVirt 中最核心的高可用功能之一,讓虛擬機器在完全不停機的情況下在節點之間自由移動。本文深入介紹其技術原理、設定方式與操作實務。
什麼是 Live Migration
Live Migration(熱遷移)指的是在虛擬機器(VM)持續運行、服務不中斷的前提下,將 VM 從一個實體節點遷移至另一個節點的技術。對於應用程式而言,這個過程幾乎感知不到,最多只有毫秒等級的短暫停頓。
主要使用場景
| 場景 | 說明 |
|---|---|
| 節點維護(Node Drain) | 需要對節點進行系統更新、核心升級或硬體維修時,先將 VM 遷移走再進行維護 |
| 負載均衡 | 叢集資源分佈不均時,將 VM 從高負載節點遷移至低負載節點 |
| 硬體故障預防 | 監測到某節點硬體有異常預警時,主動遷移 VM 以防止資料遺失 |
| 電力管理 | 離峰時段整合工作負載到較少節點,關閉空閒節點以節省電力 |
| Kubernetes Upgrade | 滾動升級 Kubernetes 節點時,逐一遷移 VM 確保服務連續性 |
Live Migration vs Cold Migration
差異說明
Live Migration(熱遷移):VM 在整個遷移過程中持續運行,guest OS 及其上的應用程式不會被中斷。停機時間(downtime)通常在數十毫秒到數百毫秒之間。
Cold Migration(冷遷移):必須先停止 VM,將磁碟映像搬移到目標節點,再重新啟動 VM。停機時間等於整個遷移所需的時間,可能長達數分鐘。
KubeVirt Live Migration 的特點
- 基於 KVM/QEMU 技術:利用 QEMU 內建的 migration 協定,成熟且穩定
- Kubernetes 原生整合:透過
VirtualMachineInstanceMigration(VMIM) CRD 管理 - 可觀測性:完整的 Prometheus metrics 供監控
- 彈性設定:透過
MigrationPolicyCRD 對不同 VM 套用不同 migration 策略 - 自動觸發:節點 drain 時自動觸發 migration,無需人工介入
技術基礎
Pre-copy Migration 算法
KubeVirt 預設使用 **pre-copy(預先複製)**算法進行記憶體遷移。其核心思想是在 VM 仍在運行的情況下,逐步將記憶體內容傳輸到目標節點。
階段 0(初始化):
- 在目標節點啟動 QEMU process(但尚未接管 VM)
- 建立 migration channel(TCP 連線)
第一輪傳輸:
- 將所有記憶體頁面複製到目標節點
- 期間 VM 仍在執行,持續產生 dirty pages
後續輪次:
- 只傳輸上一輪期間被修改(dirty)的頁面
- 每一輪的資料量理論上越來越少
停機時刻(downtime):
- 當 dirty pages 數量小到可以在 downtime budget 內傳完時
- 暫停來源 VM,傳輸最後一批 dirty pages
- 目標節點接管,恢復 VM 執行Pre-copy 的收斂問題
如果 VM 的記憶體寫入速率(dirty rate)大於網路傳輸速率,migration 將永遠無法收斂。這種情況需要啟用 auto-converge 或 post-copy 機制來解決。
Dirty Page Tracking
QEMU 利用 KVM 的 dirty page logging 功能追蹤哪些記憶體頁面在上次傳輸後被修改過:
- 啟用 dirty page bitmap
- 每次 guest 寫入記憶體,對應的 bitmap bit 被標記為 dirty
- Migration 迭代時,傳輸所有 dirty 的頁面,並清除 bitmap
- 重複直到 dirty set 夠小
Block Migration(非共享儲存)
當叢集使用非共享儲存(例如節點本地磁碟)時,不僅需要遷移記憶體,還需要遷移磁碟資料,這稱為 block migration。
Block Migration 注意事項
- Block migration 通常比純記憶體 migration 耗時更長,因為需要傳輸完整的磁碟資料
- 需要在 VM 設定中明確啟用
allowBlockMigration: true - 建議搭配高速網路使用(10GbE 以上)
- 若磁碟很大,migration 時間可能超過數小時
COW(Copy-on-Write)在磁碟遷移中的應用
在 block migration 過程中,QEMU 使用 COW 機制:
- 來源節點的磁碟繼續服務 VM 的讀寫請求
- 被修改的區塊(dirty blocks)記錄在 bitmap 中
- Migration 完成後,目標節點的磁碟映像包含完整的最終狀態
架構說明
Migration 完整架構圖
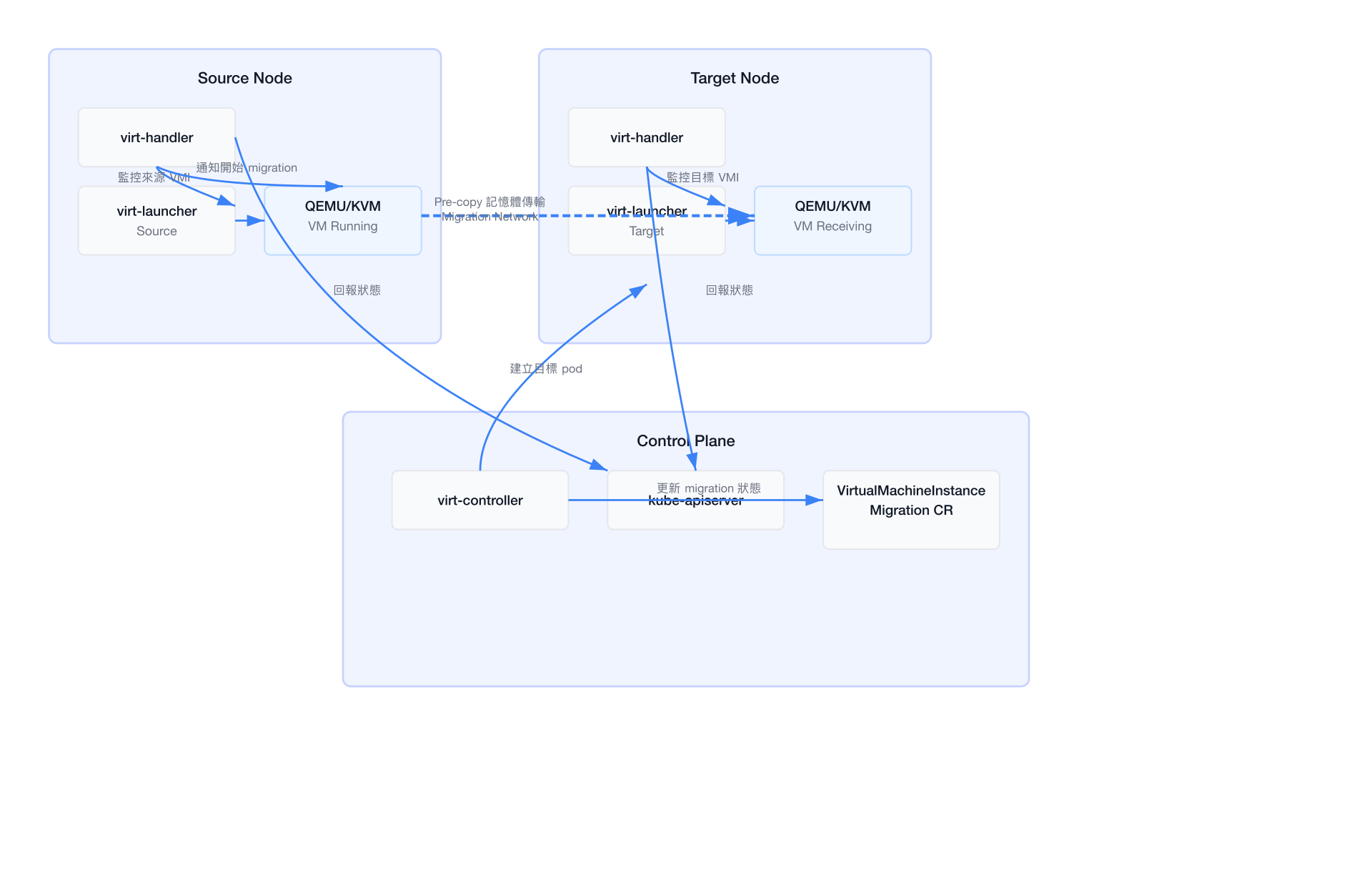
Migration Network
KubeVirt 支援使用獨立的 migration network,避免 migration 流量佔用 VM 的業務網路:
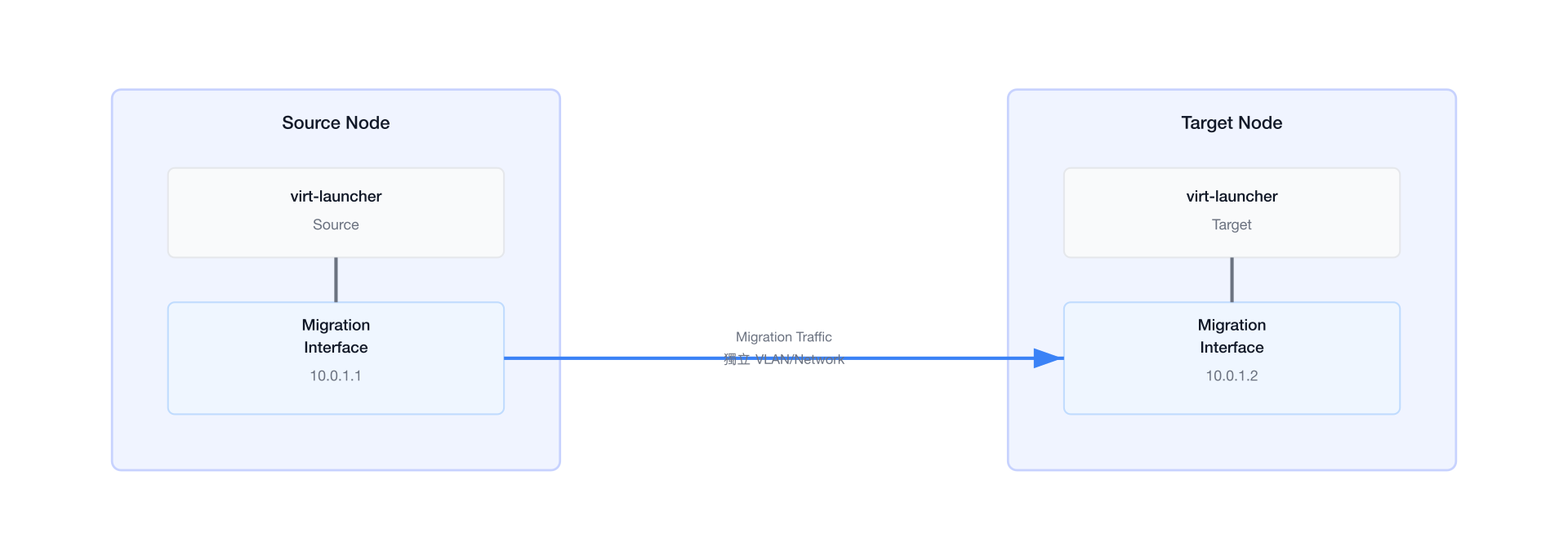
dedicatedMigrationNetwork
使用獨立 migration network 可以:
- 避免 migration 流量影響 VM 業務網路的品質
- 限制 migration 使用特定的網路路徑
- 提升安全性(migration 流量不經過業務 VLAN)
設定方式是在 KubeVirt CR 中指定 migrations.network 相關設定,並搭配 Multus 建立專用的 NetworkAttachmentDefinition。
Migration 需求條件
必要條件
| 條件 | 說明 |
|---|---|
| 共享儲存(RWX) | VM 的 PVC 需要支援 ReadWriteMany,讓兩個節點都能存取同一份磁碟 |
| 無 SR-IOV 直通 | SR-IOV VF 是硬體資源,無法跟隨 VM 遷移 |
| 無 PCI Passthrough | GPU、FPGA 等 PCI 直通設備無法遷移 |
| 無 HostDisk | 使用節點本地路徑的磁碟無法遷移 |
| 網路相容性 | 目標節點需要支援相同的網路設定(Multus, SR-IOV 等) |
可選條件
| 條件 | 設定 |
|---|---|
| Block Migration | 非 RWX 儲存時,可設定 allowBlockMigration: true 使用磁碟複製模式 |
| NUMA Topology | 若 VM 有 NUMA 親和性設定,目標節點需有相容的 NUMA 拓撲 |
不能 Migrate 的場景
SR-IOV VF 直通
SR-IOV(Single Root I/O Virtualization)允許將一個實體網卡虛擬化成多個 VF(Virtual Function)並直接分配給 VM。由於 VF 是特定物理網卡上的硬體資源,它與特定節點強綁定,無法跟隨 VM 移動到另一個節點。
SR-IOV VM 不可 Live Migrate
使用 SR-IOV 網路的 VM,其 IsMigratable condition 會為 False。嘗試 migration 將立即失敗並回報錯誤訊息:
reason: VirtualMachineInstanceIsMigratable
message: cannot migrate VMI with sriov network interfacePCI Passthrough(GPU、FPGA 等)
與 SR-IOV 類似,直接 passthrough 的 PCIe 設備(如 NVIDIA GPU、Intel FPGA)是節點本地資源,無法在節點間遷移。
HostDisk
HostDisk 類型的磁碟使用節點本地的路徑(例如 /var/data/vm.img),這份資料只存在於特定節點上,無法遷移。
# 這種設定的 VM 無法 Live Migrate
volumes:
- name: hostdisk-volume
hostDisk:
path: /var/data/my-vm.img # 節點本地路徑
type: DiskhostPID / hostNetwork
使用 hostPID 或 hostNetwork 的 VM 與節點的 namespace 強綁定,無法遷移。
檢查 IsMigratable Condition
# 查看 VMI 是否可以 migrate
kubectl get vmi <vmi-name> -o jsonpath='{.status.conditions[?(@.type=="IsMigratable")]}'回傳範例(不可遷移):
{
"lastProbeTime": "2024-01-15T10:00:00Z",
"lastTransitionTime": "2024-01-15T10:00:00Z",
"message": "cannot migrate VMI with sriov network interface",
"reason": "VirtualMachineInstanceIsMigratable",
"status": "False",
"type": "IsMigratable"
}完整 Migration 流程
狀態機圖
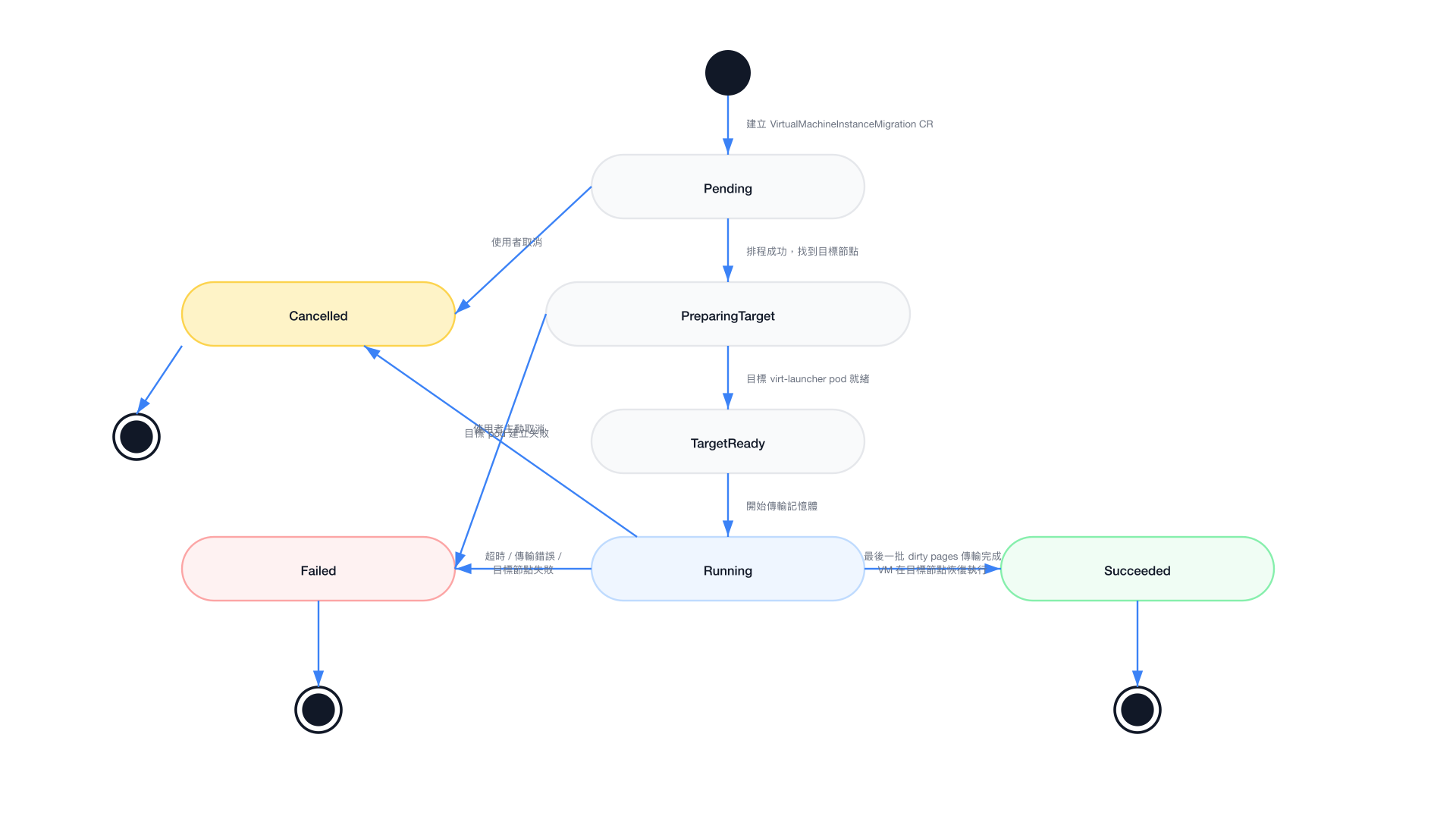
各狀態說明
| 狀態 | 說明 | 預期行動 |
|---|---|---|
| Pending | Migration 請求已建立,等待調度器找到可用目標節點 | 等待;若長時間 pending 請檢查節點資源 |
| PreparingTarget | 正在目標節點建立 virt-launcher pod,初始化 QEMU 等待接收 | 等待 pod 就緒 |
| TargetReady | 目標端就緒,QEMU migration channel 已建立 | 即將開始記憶體傳輸 |
| Running | 正在進行 pre-copy 記憶體傳輸,VM 仍在來源節點運行 | 監控傳輸進度 |
| Succeeded | Migration 完成,VM 已在目標節點恢復執行 | 確認 VM 服務正常 |
| Failed | Migration 失敗 | 查看 events 了解原因 |
| Cancelled | Migration 已被取消 | 來源 VM 繼續正常運行 |
Migration 失敗後的 VM 狀態
Migration 失敗時,VM 會繼續在來源節點正常運行,不會影響服務。失敗的 migration CR 會保留,供排查問題使用。
Migration 設定 — MigrationPolicy CRD
MigrationPolicy 是 cluster-scoped 的 CRD,可以對特定的 VMI 群組套用自訂的 migration 設定,優先級高於全域設定。
完整 MigrationPolicy 範例
apiVersion: migrations.kubevirt.io/v1alpha1
kind: MigrationPolicy
metadata:
name: high-performance-migration
spec:
# 選擇套用此 policy 的 VMI
selectors:
namespaceSelector:
matchLabels:
environment: production
virtualMachineInstanceSelector:
matchLabels:
app: critical-service
# 允許 auto-converge(自動降低 vCPU 速度以幫助 migration 收斂)
allowAutoConverge: true
# 允許 post-copy migration
allowPostCopy: false
# 每 GiB 記憶體的 migration 超時時間(秒)
# 8 GiB 記憶體 × 800 秒 = 6400 秒總超時
completionTimeoutPerGiB: 800
# Migration 頻寬限制(空白表示不限制)
bandwidthPerMigration: "1Gi"
# 是否允許 workload 中斷(例如強制暫停 VM)
allowWorkloadDisruption: falseSelector 優先順序
當多個 MigrationPolicy 的 selector 都匹配同一個 VMI 時,KubeVirt 會選擇最具體的 selector(匹配最多 label 的那個)。若優先級相同,則使用名稱字母序最小的 policy。
最佳實踐
為不同工作負載建立不同的 MigrationPolicy:
- 生產環境:低頻寬限制(避免影響業務)、啟用 auto-converge
- 測試環境:高頻寬、不限制 auto-converge
- 資料庫 VM:啟用 post-copy、較長超時時間
全域 Migration 設定(KubeVirt CR)
migrationConfiguration 欄位在 KubeVirt CR 中設定全域預設值,對所有未被 MigrationPolicy 覆蓋的 VMI 生效。
apiVersion: kubevirt.io/v1
kind: KubeVirt
metadata:
name: kubevirt
namespace: kubevirt
spec:
configuration:
migrationConfiguration:
# 每次 migration 的頻寬限制
bandwidthPerMigration: "64Mi"
# 每 GiB 記憶體的超時時間(秒)
completionTimeoutPerGiB: 800
# 每個節點同時允許的輸出 migration 數量
parallelOutboundMigrationsPerNode: 2
# 整個叢集同時允許的 migration 總數
parallelMigrationsPerCluster: 5
# Migration 進度停滯超時(秒)
# 若這段時間內沒有任何進度,視為失敗
progressTimeout: 150
# 是否允許強制 migration(即使 IsMigratable=False)
# 危險!僅用於緊急情況
unsafeMigrationOverride: false
# 節點 drain taint 的 key
# 當節點被加上此 taint 時,自動觸發 migration
nodeDrainTaintKey: "kubevirt.io/drain"
# 允許 auto-converge(全域預設)
allowAutoConverge: false
# 允許 post-copy(全域預設)
allowPostCopy: false
# 目標 pod 的 CPU request(避免影響 VM CPU)
targetNodeTopologyMatchPolicy: RequireNodesGrouping各參數說明
| 參數 | 預設值 | 說明 |
|---|---|---|
bandwidthPerMigration | 不限制 | 單次 migration 的最大頻寬 |
completionTimeoutPerGiB | 800 秒 | 超過此時間 migration 視為失敗 |
parallelOutboundMigrationsPerNode | 2 | 每節點同時輸出的 migration 上限 |
parallelMigrationsPerCluster | 5 | 叢集同時進行的 migration 總上限 |
progressTimeout | 150 秒 | 無進度時的超時 |
unsafeMigrationOverride | false | 強制 migration 開關(危險) |
parallelOutboundMigrationsPerNode 設定
此值不宜設定太高。每個 migration 都會消耗大量網路頻寬和 CPU 資源。建議:
- 10GbE 網路:最多 2-3 個並行 migration
- 25GbE 網路:最多 4-5 個並行 migration
Auto-converge 說明
問題根源
在高記憶體寫入工作負載(如資料庫、記憶體快取)中,VM 每秒產生的 dirty pages 數量可能超過網路傳輸速率,導致 migration 永遠無法收斂:
每秒 dirty rate: 2 GB/s
網路傳輸速率: 1 GB/s
結果: dirty pages 越積越多,migration 永遠無法完成Auto-converge 機制
當 KVM 偵測到 migration 收斂困難時,會自動降低 guest 的 vCPU 執行速度(throttling),從而降低 dirty rate:
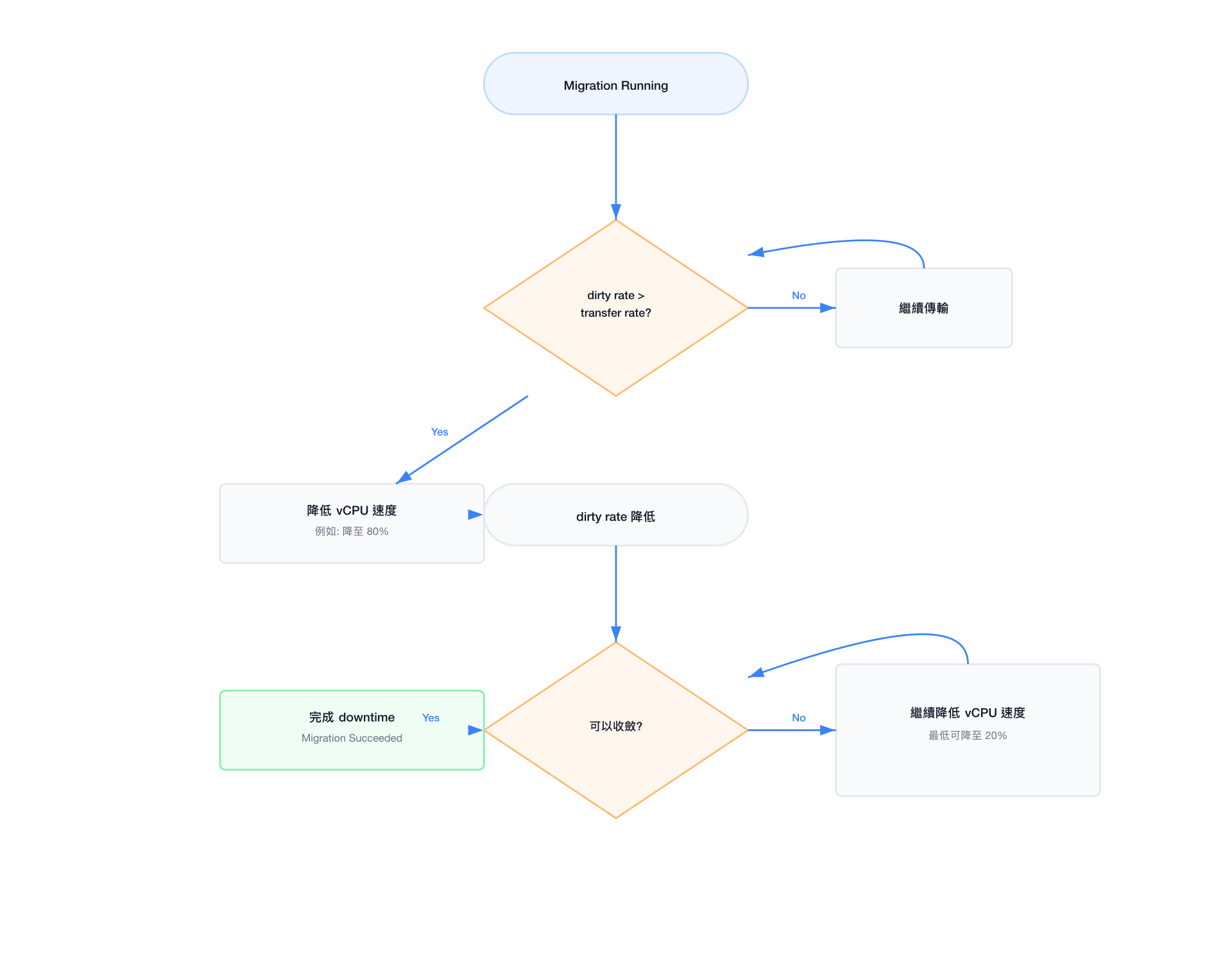
啟用方式
# 透過 MigrationPolicy(推薦)
spec:
allowAutoConverge: true
# 或透過 KubeVirt CR 全域設定
spec:
configuration:
migrationConfiguration:
allowAutoConverge: trueAuto-converge 對效能的影響
啟用 auto-converge 時,如果 migration 遭遇收斂困難,VM 的 CPU 效能會被自動降低,這會直接影響 guest OS 及其應用程式的效能。
對於 SLA 嚴格的生產環境,建議:
- 先嘗試在業務低峰期進行 migration
- 確保有足夠的網路頻寬
- 謹慎評估是否啟用 auto-converge
Post-copy Migration 說明
原理
Post-copy 是 pre-copy 的替代(或補充)方案,其核心思想是:先切換,後補傳。
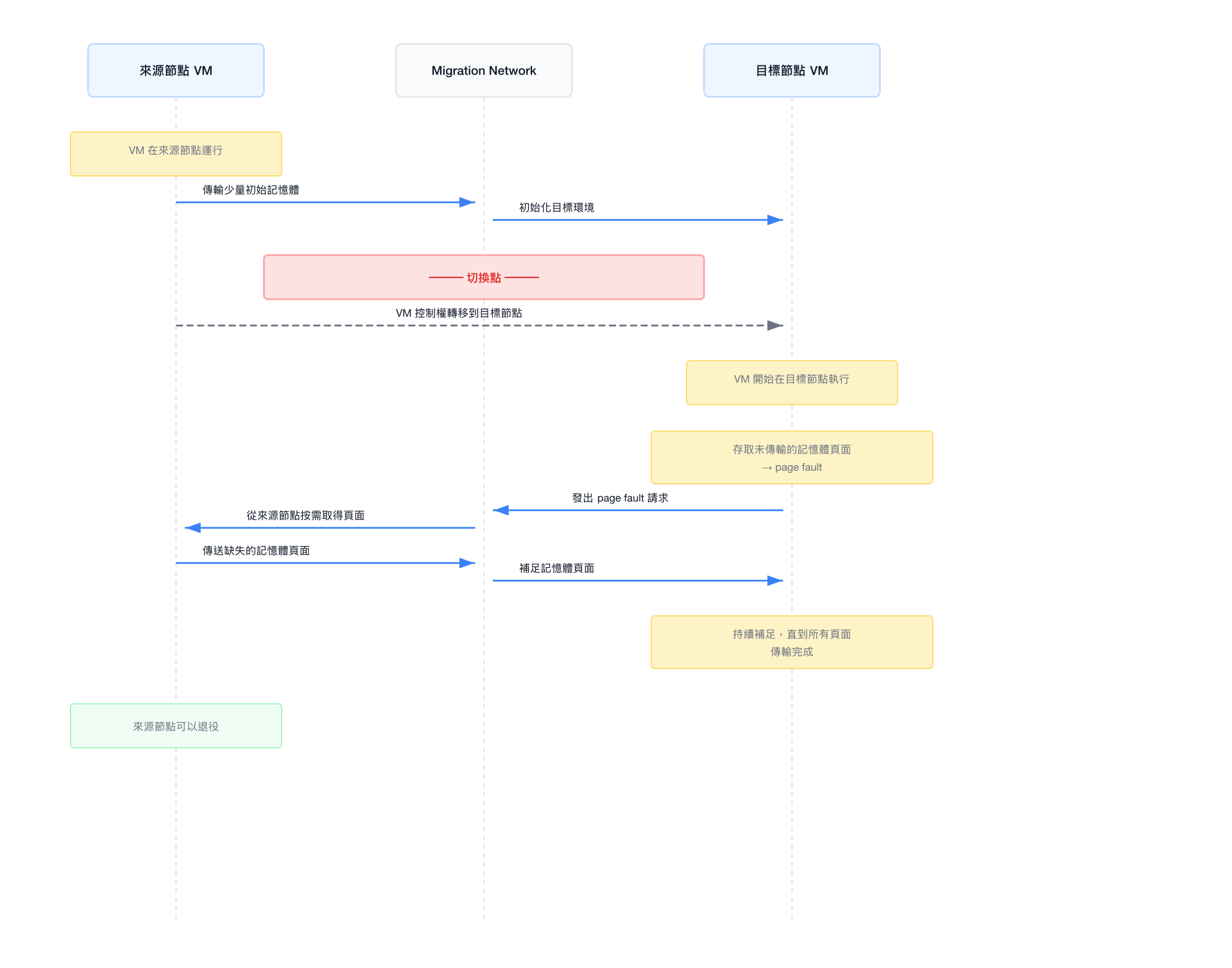
Post-copy 的優缺點
| Pre-copy | Post-copy | |
|---|---|---|
| Downtime | 較長(等待 dirty set 收斂) | 極短(直接切換) |
| Total 傳輸量 | 可能很大(多輪 dirty pages) | 每頁只傳輸一次 |
| 來源節點依賴 | 切換後即釋放 | 切換後仍需存取 |
| 節點故障風險 | 低(失敗回到來源節點) | 高(故障可能導致 VM crash) |
| 網路延遲影響 | 低 | 高(page fault 需即時響應) |
Post-copy 風險警告
在 post-copy 進行中,如果來源節點或網路連線發生故障,目標節點上的 VM 將會立即 crash,因為它無法取得仍在來源節點的記憶體頁面。
僅在以下場景考慮啟用 post-copy:
- 網路非常穩定可靠
- VM 的 downtime 要求極為嚴格
- 有完善的監控和快速回應機制
啟用方式
spec:
allowPostCopy: trueKubeVirt 預設會先嘗試 pre-copy,若 pre-copy 無法在超時前完成,才會自動切換至 post-copy(如果已啟用)。
Multifd(多路並行傳輸)
說明
Multifd(Multiple file descriptors)使用多個 TCP channel 並行傳輸記憶體頁面,充分利用現代高頻寬網路(25GbE、100GbE):
傳統方式(Single channel):
CH1: Page1 → Page2 → Page3 → Page4 → ...
Multifd(8 channels):
CH1: Page1 → Page9 → Page17 → ...
CH2: Page2 → Page10 → Page18 → ...
CH3: Page3 → Page11 → Page19 → ...
...
CH8: Page8 → Page16 → Page24 → ...Multifd 預設設定
KubeVirt 預設啟用 multifd,使用 8 個 channel。在 10GbE 以上的網路環境中,multifd 能顯著提升 migration 速度。低頻寬網路(1GbE)中效果不明顯。
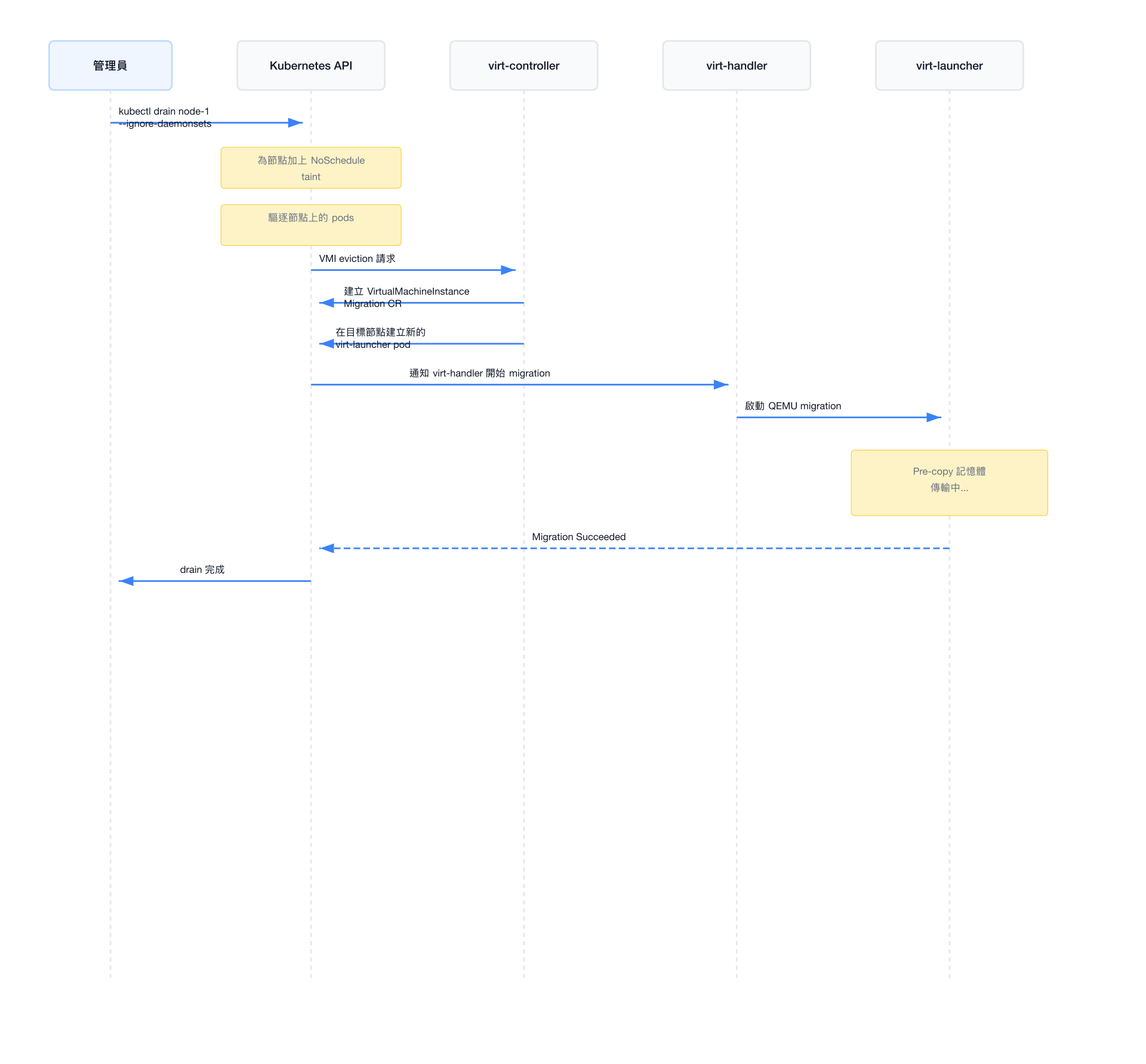
節點驅逐觸發的自動 Migration
EvictionStrategy 設定
evictionStrategy 決定當節點被驅逐(drain)時,VMI 的行為:
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: my-vm
spec:
template:
spec:
evictionStrategy: LiveMigrate # 或 LiveMigrateIfPossible / None / External| 值 | 說明 |
|---|---|
LiveMigrate | 必須 live migrate,若無法 migrate 則 drain 失敗 |
LiveMigrateIfPossible | 盡量 live migrate,若不可能則直接刪除 VMI |
None | 不做任何處理,節點 drain 時直接驅逐 VMI |
External | 由外部工具處理(例如 cluster autoscaler) |
kubectl drain 觸發流程
Node Maintenance Operator 整合
Node Maintenance Operator
KubeVirt 可以與 Node Maintenance Operator (NMO) 整合,提供更完善的節點維護工作流程:
# 安裝 Node Maintenance Operator
kubectl apply -f https://github.com/medik8s/node-maintenance-operator/releases/latest/download/...
# 建立 NodeMaintenance CR 開始維護
kubectl apply -f - <<EOF
apiVersion: nodemaintenance.medik8s.io/v1beta1
kind: NodeMaintenance
metadata:
name: maintenance-node-1
spec:
nodeName: node-1
reason: "Scheduled kernel upgrade"
EOFNMO 會自動處理:
- 排空節點(drain)
- 等待所有 migration 完成
- 標記節點為維護中
- 維護完成後,重新允許排程
監控 Migration 進度
Prometheus Metrics
| Metric | 說明 |
|---|---|
kubevirt_vmi_migration_data_bytes | Migration 傳輸的總資料量(bytes) |
kubevirt_vmi_migration_data_processed | 已處理的 dirty 資料量(bytes) |
kubevirt_vmi_migration_dirty_memory_rate | 當前 dirty memory 產生速率(bytes/s) |
kubevirt_vmi_migration_transfer_rate | 實際傳輸速率(bytes/s) |
kubevirt_vmi_migrations_in_pending_phase | 目前 pending 的 migration 數量 |
kubevirt_vmi_migrations_in_running_phase | 目前 running 的 migration 數量 |
kubevirt_vmi_migration_succeeded | 歷史成功 migration 總數 |
kubevirt_vmi_migration_failed | 歷史失敗 migration 總數 |
判斷 Migration 是否能收斂
使用以下 PromQL 查詢可以判斷 migration 是否在收斂中:
# 傳輸速率 vs dirty rate
# 若 transfer_rate > dirty_rate,migration 將收斂
kubevirt_vmi_migration_transfer_rate - kubevirt_vmi_migration_dirty_memory_rate
# 若結果為正數:migration 正在收斂
# 若結果為負數:migration 可能無法完成,考慮啟用 auto-convergekubectl 查看 Migration 狀態
# 列出所有 migration
kubectl get vmim -A
# 查看特定 migration 的詳細狀態
kubectl describe vmim <migration-name> -n <namespace>
# 即時監控 migration 狀態
watch kubectl get vmim -n <namespace>輸出範例:
NAME VMI PHASE REASON
kubevirt-migrate-vmi-abcdef my-vm-vmi Running完整操作範例
1. 手動觸發 Migration
# 建立 VirtualMachineInstanceMigration
apiVersion: kubevirt.io/v1
kind: VirtualMachineInstanceMigration
metadata:
name: migration-job-1
namespace: default
spec:
vmiName: my-vm-vmi # 目標 VMI 名稱kubectl apply -f migration.yaml
# 或使用 virtctl
virtctl migrate my-vm2. 查看 Migration 狀態
# 基本狀態
kubectl get vmim migration-job-1 -n default
# 詳細資訊
kubectl describe vmim migration-job-1 -n default
# 查看 events
kubectl get events -n default --field-selector reason=Migrating
# 查看 VMI 目前所在節點
kubectl get vmi my-vm-vmi -n default -o jsonpath='{.status.nodeName}'3. 取消進行中的 Migration
# 刪除 VMIM CR 即可取消
kubectl delete vmim migration-job-1 -n default
# 或使用 virtctl
virtctl migrate-cancel my-vm4. 設定 MigrationPolicy
apiVersion: migrations.kubevirt.io/v1alpha1
kind: MigrationPolicy
metadata:
name: production-migration-policy
spec:
selectors:
namespaceSelector:
matchLabels:
tier: production
virtualMachineInstanceSelector:
matchLabels:
workload: database
allowAutoConverge: true
allowPostCopy: false
completionTimeoutPerGiB: 1200
bandwidthPerMigration: "512Mi"kubectl apply -f migration-policy.yaml
# 確認 policy 已建立
kubectl get migrationpolicy5. 更新全域 Migration 設定
kubectl patch kubevirt kubevirt -n kubevirt --type=merge -p '{
"spec": {
"configuration": {
"migrationConfiguration": {
"bandwidthPerMigration": "128Mi",
"parallelMigrationsPerCluster": 3,
"parallelOutboundMigrationsPerNode": 1,
"allowAutoConverge": true
}
}
}
}'6. 完整 Migration 診斷流程
# Step 1: 確認 VMI 是否可以 migrate
kubectl get vmi <vmi-name> -o jsonpath='{.status.conditions[?(@.type=="IsMigratable")].status}'
# Step 2: 確認節點有可用資源
kubectl describe node <target-node> | grep -A 5 "Allocatable"
# Step 3: 建立 migration
virtctl migrate <vm-name>
# Step 4: 監控進度
watch -n 2 kubectl get vmim -n <namespace>
# Step 5: 若失敗,查看 events
kubectl describe vmim <migration-name> -n <namespace>
kubectl get events -n <namespace> --sort-by=.lastTimestamp | tail -20
# Step 6: 查看 virt-controller logs
kubectl logs -n kubevirt deployment/virt-controller --tail=100 | grep -i migration
# Step 7: 查看 virt-handler logs(來源節點)
kubectl logs -n kubevirt daemonset/virt-handler --tail=100 | grep -i migrationMigration 最佳實踐總結
- 共享儲存:盡量使用 RWX 的儲存後端(Ceph RBD with ReadWriteMany、NFS 等),避免 block migration
- 網路頻寬:確保節點間有足夠頻寬(10GbE+),考慮使用 dedicated migration network
- 時機選擇:在業務低峰期進行大量 migration
- 監控告警:配置 Prometheus 告警,監控 migration 失敗率和耗時
- 逐步驗證:在正式環境大規模使用前,先在測試環境驗證 migration 成功率