效能調校指南 — 榨乾每一分效能
本章導讀
KubeVirt 運行在 QEMU/KVM 之上,本身已經提供接近原生的虛擬化效能。然而,要達到生產環境的嚴苛效能要求,需要針對 CPU、記憶體、儲存和網路進行細緻的調校。本章將深入每個層面,提供完整的最佳化策略。
CPU 效能最佳化
CPU Pinning(dedicatedCPUPlacement)
CPU Pinning 將虛擬 CPU(vCPU)綁定到特定的物理 CPU 核心,避免 vCPU 在不同物理核心之間遷移造成的 cache miss 和排程延遲。
原理說明:
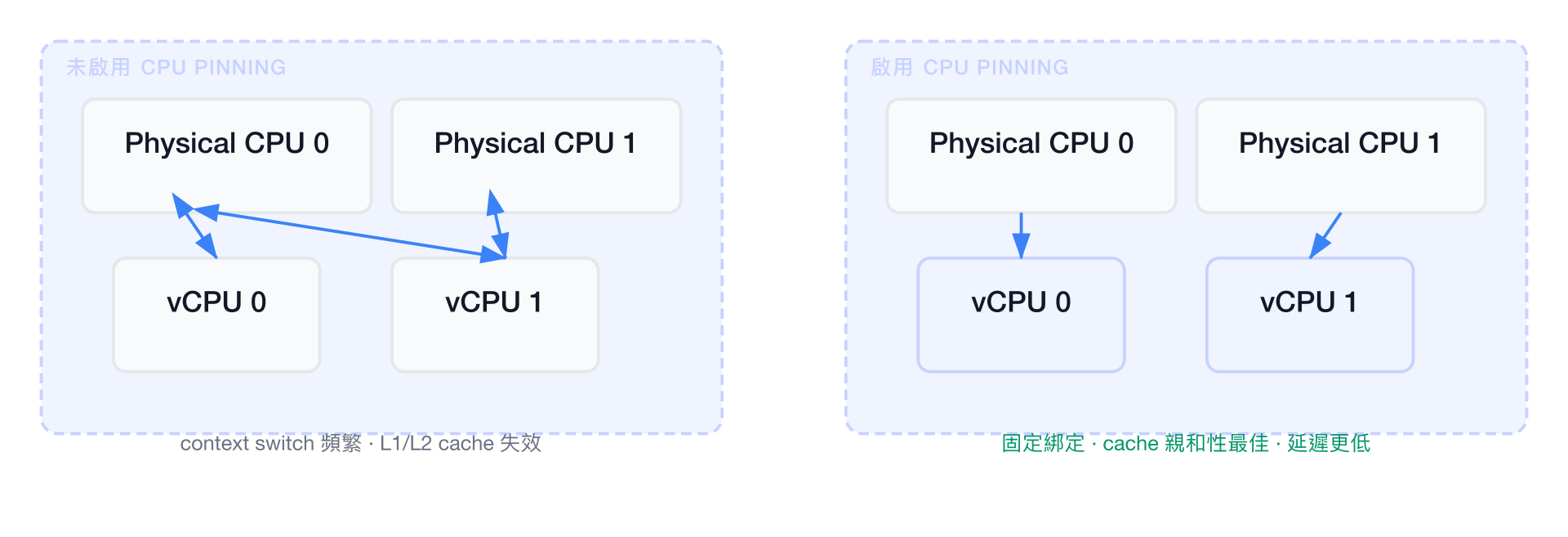
配置方式:
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: high-perf-vm
spec:
template:
spec:
domain:
cpu:
cores: 4
sockets: 1
threads: 1
dedicatedCPUPlacement: true
model: host-passthrough
numa:
guestMappingPassthrough: {}
memory:
hugepages:
pageSize: "1Gi"
guest: 8Gi前提條件
啟用 CPU Pinning 需要:
- Kubernetes 節點啟用
staticCPU Manager Policy:--cpu-manager-policy=static kubelet設定預留 CPU:--reserved-cpus=0-1(為系統和 Kubernetes 元件保留 CPU)- VM 的 CPU 請求必須是整數(不能是小數如 0.5)
- 節點需要有足夠的「可分配」CPU 核心
適用場景:
- DPDK 高效能封包處理
- 即時運算、低延遲交易系統
- 電信 NFV / VNF 工作負載
- 資料庫(低延遲查詢)
Emulator Thread Isolation(isolateEmulatorThread)
QEMU 除了 vCPU 執行緒外,還有一個主要的「emulator thread」負責 IO 模擬和管理工作。isolateEmulatorThread 將這個執行緒分配到獨立的 CPU 核心,避免與 vCPU 執行緒競爭。
spec:
template:
spec:
domain:
cpu:
cores: 4
dedicatedCPUPlacement: true
isolateEmulatorThread: true # emulator thread 獨佔一個 CPU效能影響
啟用 isolateEmulatorThread 會額外消耗一個 CPU 核心(上例實際佔用 5 個核心),但可以避免 emulator thread 搶佔 vCPU 的執行時間,對 IO 密集型工作負載特別有效。
NUMA Topology
Non-Uniform Memory Access(NUMA)架構中,CPU 存取本地記憶體比遠端記憶體快很多。正確的 NUMA 對齊可以顯著提升效能。
spec:
template:
spec:
domain:
cpu:
cores: 8
sockets: 2
threads: 1
dedicatedCPUPlacement: true
numa:
guestMappingPassthrough: {} # 將 Host NUMA 拓撲直接映射給 Guest
memory:
hugepages:
pageSize: "1Gi"
guest: 16Gi# 確認節點 NUMA 拓撲
kubectl get node worker-01 -o json | jq '.status.allocatable'
# 在 VM 內驗證 NUMA 配置
numactl --hardwareNUMA 錯誤對齊的影響
當 vCPU 和記憶體分佈在不同 NUMA 節點時,記憶體存取延遲可能增加 40-100%,嚴重影響資料庫和高效能運算工作負載。務必確保 CPU Pinning 和 HugePages 配合 NUMA 對齊使用。
CPU Model 選擇
| 模式 | 說明 | 效能 | 可遷移性 |
|---|---|---|---|
host-passthrough | 完整暴露 Host CPU 特性給 Guest | ★★★★★ | ❌ 僅同型號 CPU 間可遷移 |
host-model | 使用最接近 Host CPU 的已知模型 | ★★★★☆ | ⚠️ 同代 CPU 間可遷移 |
| 自定義模型 | 指定特定 CPU 型號和 feature flags | ★★★☆☆ | ✅ 跨不同硬體可遷移 |
# host-passthrough:最佳效能(推薦用於不需要遷移的場景)
spec:
domain:
cpu:
model: host-passthrough
# host-model:平衡效能與遷移性
spec:
domain:
cpu:
model: host-model
# 自定義模型:完全控制 CPU feature
spec:
domain:
cpu:
model: Skylake-Server-v1
features:
- name: avx512f
policy: require
- name: ssse3
policy: requireReal-time CPU(RT Kernel 場景)
對於需要確定性延遲的工作負載(如電信 5G vRAN),KubeVirt 支援 real-time 配置:
spec:
template:
spec:
domain:
cpu:
cores: 4
dedicatedCPUPlacement: true
isolateEmulatorThread: true
realtime:
mask: "0-2" # vCPU 0-2 為 real-time,vCPU 3 為 housekeeping
numa:
guestMappingPassthrough: {}RT Kernel 需求
使用 real-time CPU 需要節點安裝 RT kernel(如 kernel-rt),並配合 tuned 或 performance-addon-operator 調整系統配置。
記憶體效能最佳化
HugePages(2Mi / 1Gi)
原理: 一般的記憶體分頁大小為 4KB,當 VM 使用大量記憶體時,TLB(Translation Lookaside Buffer)需要管理大量的分頁映射,導致 TLB miss 頻繁發生。HugePages 使用 2MB 或 1GB 的大分頁,大幅減少 TLB 條目數量。
4KB 分頁(8GB 記憶體): 1GB HugePages(8GB 記憶體):
┌────────────────────────┐ ┌────────────────────────┐
│ 2,097,152 個分頁條目 │ │ 8 個分頁條目 │
│ TLB miss 頻繁 │ │ TLB miss 極少 │
│ 效能損失 5-15% │ │ 接近零開銷 │
└────────────────────────┘ └────────────────────────┘節點配置(Node 層級):
# 方法 1:啟動時配置(推薦)
# 在 kernel 參數中加入:
GRUB_CMDLINE_LINUX="hugepagesz=1G hugepages=32 hugepagesz=2M hugepages=1024"
# 方法 2:執行時配置(僅 2MB 頁面)
echo 1024 > /proc/sys/vm/nr_hugepages
# 驗證 HugePages 配置
cat /proc/meminfo | grep HugePages
# HugePages_Total: 32
# HugePages_Free: 30
# HugePages_Rsvd: 0
# Hugepagesize: 1048576 kBVM 配置:
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: hugepages-vm
spec:
template:
spec:
domain:
memory:
hugepages:
pageSize: "1Gi" # 或 "2Mi"
guest: 8Gi
resources:
requests:
memory: "8Gi"1Gi vs 2Mi 選擇
- 1Gi HugePages:最佳 TLB 效能,但需要連續的 1GB 記憶體區塊,可能導致分配失敗。適合大記憶體 VM
- 2Mi HugePages:更靈活的分配,適合中小型 VM。效能略低於 1Gi 但遠優於普通 4KB 分頁
Memory Balloon 停用
Memory Balloon(記憶體氣球)允許 Host 動態回收 Guest 未使用的記憶體。但在高效能場景中,Balloon 操作會導致不可預期的記憶體壓力:
spec:
template:
spec:
domain:
devices:
autoattachMemBalloon: false # 停用 memory balloon停用 Balloon 的影響
停用 Balloon 後,VM 分配的記憶體將不會被 Host 回收,即使 Guest 內部未使用。這會降低整體記憶體使用效率,但確保 VM 的記憶體效能穩定。
Memory Overcommit
# 允許 overcommit(開發 / 測試環境)
spec:
domain:
memory:
guest: 8Gi
resources:
requests:
memory: 4Gi # 實際預留僅 4Gi,但 Guest 看到 8Gi
# 透過 overcommitGuestOverhead 進一步控制生產環境注意
Memory Overcommit 在生產環境中存在風險。當多個 VM 同時使用大量記憶體時,可能觸發 OOM Killer,導致 VM 被強制終止。生產環境建議 requests = guest memory。
儲存效能最佳化
IO Threads(ioThreadsPolicy)
IO Threads 將磁碟的 IO 處理從 QEMU 主執行緒中分離出來,使用獨立的執行緒處理 IO 操作。
| 策略 | 說明 | 適用場景 |
|---|---|---|
dedicated | 每個磁碟一個專屬 IO Thread | 多磁碟、高 IOPS 場景 |
auto | 自動分配(一個 IO Thread 可服務多個磁碟) | 一般場景 |
shared | 所有磁碟共用一個 IO Thread | 簡單場景 |
spec:
template:
spec:
domain:
ioThreadsPolicy: dedicated # 或 auto / shared
devices:
disks:
- name: rootdisk
disk:
bus: virtio
io: threads # 啟用 IO Threads
- name: datadisk
disk:
bus: virtio
io: threadsCache 模式
| 模式 | 效能 | 資料安全性 | 說明 |
|---|---|---|---|
none | ★★★★★ | ★★★★★ | 繞過 Host page cache,直接 IO。最推薦 |
writethrough | ★★★☆☆ | ★★★★★ | 寫入同時到 cache 和磁碟,安全但慢 |
writeback | ★★★★☆ | ★★☆☆☆ | 寫入先到 cache,非同步刷到磁碟。快但有資料丟失風險 |
spec:
domain:
devices:
disks:
- name: rootdisk
disk:
bus: virtio
cache: none # 推薦:直接 IO
- name: tempdisk
disk:
bus: virtio
cache: writeback # 暫存磁碟可接受風險換取效能Cache Mode 選擇建議
- 生產資料庫:
cache: none(資料安全最重要) - 暫存 / 開發環境:
cache: writeback(效能優先) - 需要 Live Migration:
cache: none(某些 cache 模式不支援遷移)
Disk Bus 選擇
| Bus 類型 | 最大效能 | 功能支援 | 說明 |
|---|---|---|---|
| virtio-blk | ★★★★★ | 基本 | 最高效能,推薦用於主要磁碟 |
| virtio-scsi | ★★★★☆ | 豐富 | 支援 discard / hotplug / 多 LUN |
| sata | ★★☆☆☆ | 相容 | 用於不支援 VirtIO 的 OS |
| usb | ★☆☆☆☆ | 相容 | 僅用於可卸除媒體 |
spec:
domain:
devices:
disks:
- name: rootdisk
disk:
bus: virtio # virtio-blk,最佳效能
- name: datadisk
disk:
bus: scsi # virtio-scsi,支援 hotplug 和 discard
dedicatedIOThread: true
- name: cddisk
cdrom:
bus: sata # CD-ROM 使用 SATABlock vs Filesystem PVC
# Block mode(推薦高效能場景)
# 消除 filesystem 層的開銷,直接存取 raw block device
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: block-pvc
spec:
accessModes:
- ReadWriteMany
volumeMode: Block # ← 關鍵差異
resources:
requests:
storage: 50Gi
storageClassName: ceph-block
# Filesystem mode(預設)
# 透過 filesystem(ext4/xfs)層存取
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fs-pvc
spec:
accessModes:
- ReadWriteMany
volumeMode: Filesystem # 預設值
resources:
requests:
storage: 50GiBlock vs Filesystem 效能差異
Block mode 可減少約 5-10% 的 IO 開銷,因為省去了 Host 端的 filesystem 層。對於資料庫和高 IOPS 工作負載,這個差異非常顯著。但 Block mode 不支援 VM 磁碟的直接檢查(因為沒有 Host 層的 filesystem)。
網路效能最佳化
VirtIO 多佇列(NetworkInterfaceMultiQueue)
多佇列讓多個 vCPU 同時處理網路封包,提升高併發場景下的網路吞吐量:
spec:
template:
spec:
domain:
devices:
networkInterfaceMultiqueue: true # 啟用多佇列
interfaces:
- name: default
masquerade: {}佇列數量
佇列數量自動等於 vCPU 數量。例如 4 vCPU 的 VM 會有 4 個收發佇列。在高流量場景下,多佇列可提升 2-4 倍 的網路吞吐量。
SR-IOV(硬體直通)
SR-IOV 讓 VM 直接存取物理網卡的虛擬功能(VF),完全繞過軟體交換,達到接近線速的網路效能:
# 前提:安裝 SR-IOV Network Operator 並建立 SriovNetworkNodePolicy
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: sriov-net
annotations:
k8s.v1.cni.cncf.io/resourceName: openshift.io/mlnx_sriov
spec:
config: |
{
"type": "sriov",
"cniVersion": "0.3.1",
"name": "sriov-network",
"vlan": 100
}
---
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: sriov-vm
spec:
template:
spec:
domain:
devices:
interfaces:
- name: sriov-nic
sriov: {} # SR-IOV 直通
resources:
requests:
openshift.io/mlnx_sriov: "1" # 請求一個 VF
limits:
openshift.io/mlnx_sriov: "1"
networks:
- name: sriov-nic
multus:
networkName: sriov-netSR-IOV 限制
使用 SR-IOV 的 VM 無法進行 Live Migration,因為 VF 是直接綁定到物理硬體的。如果需要遷移能力,請考慮使用 OVS-DPDK 作為替代方案。
DPDK 與 OVS-DPDK
DPDK(Data Plane Development Kit)繞過核心網路堆疊,在使用者空間直接處理封包。OVS-DPDK 結合 Open vSwitch 和 DPDK,提供高效能的虛擬交換:
# OVS-DPDK 需要 HugePages 和 CPU Pinning
spec:
template:
spec:
domain:
cpu:
cores: 4
dedicatedCPUPlacement: true
memory:
hugepages:
pageSize: "1Gi"
guest: 4Gi
devices:
interfaces:
- name: dpdk-net
vhostuser: {} # vhost-user 介面
networks:
- name: dpdk-net
multus:
networkName: dpdk-networkJumbo Frame 配置
# 在 NetworkAttachmentDefinition 中設定 MTU
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: jumbo-net
spec:
config: |
{
"cniVersion": "0.3.1",
"type": "bridge",
"bridge": "br-data",
"mtu": 9000,
"ipam": {
"type": "whereabouts",
"range": "10.10.10.0/24"
}
}綜合效能配置範例
資料庫 VM(高 IOPS)
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: database-vm
labels:
workload: database
spec:
running: true
template:
spec:
evictionStrategy: LiveMigrate
domain:
cpu:
cores: 8
sockets: 1
threads: 1
dedicatedCPUPlacement: true
isolateEmulatorThread: true
model: host-passthrough
numa:
guestMappingPassthrough: {}
memory:
hugepages:
pageSize: "1Gi"
guest: 32Gi
devices:
autoattachMemBalloon: false
networkInterfaceMultiqueue: true
disks:
- name: rootdisk
disk:
bus: virtio
cache: none
io: threads
- name: datadisk
disk:
bus: virtio
cache: none
io: threads
dedicatedIOThread: true
interfaces:
- name: default
masquerade: {}
ioThreadsPolicy: dedicated
networks:
- name: default
pod: {}
volumes:
- name: rootdisk
dataVolume:
name: db-rootdisk
- name: datadisk
persistentVolumeClaim:
claimName: db-data-block # Block mode PVC網路功能 VM(NFV / VNF)
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: vnf-router
labels:
workload: nfv
spec:
running: true
template:
spec:
domain:
cpu:
cores: 4
dedicatedCPUPlacement: true
isolateEmulatorThread: true
model: host-passthrough
numa:
guestMappingPassthrough: {}
realtime:
mask: "0-2"
memory:
hugepages:
pageSize: "1Gi"
guest: 8Gi
devices:
autoattachMemBalloon: false
interfaces:
- name: mgmt
masquerade: {}
- name: data-in
sriov: {}
- name: data-out
sriov: {}
resources:
requests:
intel.com/sriov_netdevice: "2"
limits:
intel.com/sriov_netdevice: "2"
networks:
- name: mgmt
pod: {}
- name: data-in
multus:
networkName: sriov-data-in
- name: data-out
multus:
networkName: sriov-data-outAI / ML GPU VM
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: ml-training-vm
labels:
workload: ai-ml
spec:
running: true
template:
spec:
domain:
cpu:
cores: 16
dedicatedCPUPlacement: true
model: host-passthrough
numa:
guestMappingPassthrough: {}
memory:
hugepages:
pageSize: "1Gi"
guest: 64Gi
devices:
autoattachMemBalloon: false
gpus:
- name: gpu1
deviceName: nvidia.com/A100
disks:
- name: rootdisk
disk:
bus: virtio
cache: none
io: threads
interfaces:
- name: default
masquerade: {}
ioThreadsPolicy: auto
networks:
- name: default
pod: {}
volumes:
- name: rootdisk
dataVolume:
name: ml-rootdisk一般用途 VM(開發 / 測試)
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: dev-vm
labels:
workload: general
spec:
running: true
template:
spec:
domain:
cpu:
cores: 2
memory:
guest: 4Gi
devices:
disks:
- name: rootdisk
disk:
bus: virtio
interfaces:
- name: default
masquerade: {}
networks:
- name: default
pod: {}
volumes:
- name: rootdisk
containerDisk:
image: quay.io/containerdisks/ubuntu:22.04效能基準測試方法
CPU 基準測試
# 使用 sysbench
sysbench cpu --cpu-max-prime=20000 --threads=4 run
# 使用 stress-ng(更全面)
stress-ng --cpu 4 --cpu-method all --metrics-brief --timeout 60s
# 比較結果:有無 CPU Pinning 的差異
# 預期改善:延遲降低 20-40%,抖動減少 80%+記憶體基準測試
# 使用 stream(記憶體頻寬測試)
git clone https://github.com/jeffhammond/STREAM.git
cd STREAM && gcc -O3 -fopenmp stream.c -o stream
OMP_NUM_THREADS=4 ./stream
# 比較結果:HugePages vs 普通分頁
# 預期改善:記憶體頻寬提升 5-15%儲存基準測試
# 使用 fio(隨機讀寫 IOPS 測試)
fio --name=randrw --ioengine=libaio --direct=1 \
--bs=4k --size=1G --numjobs=4 --runtime=60 \
--rw=randrw --rwmixread=70 --group_reporting
# 循序讀寫吞吐量測試
fio --name=seqrw --ioengine=libaio --direct=1 \
--bs=1M --size=4G --numjobs=1 --runtime=60 \
--rw=readwrite --group_reporting
# 比較項目:
# Block vs Filesystem PVC
# IO Threads 啟用 vs 未啟用
# 不同 cache 模式網路基準測試
# 使用 iperf3
# Server 端
iperf3 -s
# Client 端(TCP 吞吐量)
iperf3 -c <server-ip> -t 30 -P 4
# Client 端(UDP 延遲)
iperf3 -c <server-ip> -u -b 10G -t 30
# 使用 netperf(延遲測試)
netperf -H <server-ip> -t TCP_RR -l 30效能監控
關鍵 Prometheus 指標
# === CPU 指標 ===
# VM CPU 使用率(每個 vCPU)
rate(kubevirt_vmi_cpu_usage_seconds_total[5m])
# CPU steal time(被 Host 搶佔的 CPU 時間)
rate(kubevirt_vmi_cpu_steal_time_seconds_total[5m])
# === 記憶體指標 ===
# VM 記憶體使用量
kubevirt_vmi_memory_used_bytes
# Memory balloon 目前大小
kubevirt_vmi_memory_actual_balloon_bytes
# 可用記憶體
kubevirt_vmi_memory_available_bytes
# === 儲存指標 ===
# 磁碟 IOPS
rate(kubevirt_vmi_storage_iops_read_total[5m])
rate(kubevirt_vmi_storage_iops_write_total[5m])
# 磁碟吞吐量
rate(kubevirt_vmi_storage_read_traffic_bytes_total[5m])
rate(kubevirt_vmi_storage_write_traffic_bytes_total[5m])
# 磁碟延遲
rate(kubevirt_vmi_storage_read_times_seconds_total[5m]) /
rate(kubevirt_vmi_storage_iops_read_total[5m])
# === 網路指標 ===
# 網路吞吐量
rate(kubevirt_vmi_network_receive_bytes_total[5m])
rate(kubevirt_vmi_network_transmit_bytes_total[5m])
# 封包丟失
rate(kubevirt_vmi_network_receive_packets_dropped_total[5m])
rate(kubevirt_vmi_network_transmit_packets_dropped_total[5m])
# === 遷移指標 ===
# 遷移資料傳輸速率
kubevirt_vmi_migration_data_processed_bytes
kubevirt_vmi_migration_data_remaining_bytesGrafana Dashboard 配置建議
推薦 Dashboard
社群提供了多個預建的 KubeVirt Grafana Dashboard:
- KubeVirt VM Dashboard:單一 VM 的詳細效能指標
- KubeVirt Cluster Overview:叢集層級的 VM 總覽
- KubeVirt Migration Dashboard:遷移狀態和效能追蹤
可從 Grafana Dashboard 市集 搜尋 "kubevirt" 找到最新版本。
# 建議的告警規則
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: kubevirt-performance-alerts
spec:
groups:
- name: kubevirt-performance
rules:
- alert: VMHighCPUUsage
expr: rate(kubevirt_vmi_cpu_usage_seconds_total[5m]) > 0.9
for: 10m
labels:
severity: warning
annotations:
summary: "VM {{ $labels.name }} CPU 使用率超過 90%"
- alert: VMHighMemoryUsage
expr: kubevirt_vmi_memory_used_bytes / kubevirt_vmi_memory_available_bytes > 0.95
for: 5m
labels:
severity: critical
annotations:
summary: "VM {{ $labels.name }} 記憶體使用率超過 95%"
- alert: VMHighDiskLatency
expr: |
rate(kubevirt_vmi_storage_read_times_seconds_total[5m]) /
rate(kubevirt_vmi_storage_iops_read_total[5m]) > 0.01
for: 5m
labels:
severity: warning
annotations:
summary: "VM {{ $labels.name }} 磁碟讀取延遲超過 10ms"