Observability — 監控、指標與日誌
完善的可觀測性(Observability)是運維 KubeVirt 叢集的基礎。本文涵蓋所有 Prometheus 指標、日誌排查技巧、Grafana Dashboard 設定,以及實用的診斷指令集合。
KubeVirt Prometheus Metrics 完整列表
KubeVirt 透過 virt-handler 和各元件暴露 Prometheus metrics。以下按類別整理所有重要指標。
VM/VMI 狀態指標
| Metric 名稱 | 類型 | 標籤 | 說明 |
|---|---|---|---|
kubevirt_number_of_vms | Gauge | — | 叢集中 VirtualMachine 的總數 |
kubevirt_vmi_phase_count | Gauge | phase, node, os, workload, flavor | 各 phase 的 VMI 數量(Running/Pending 等) |
kubevirt_vmi_non_evictable | Gauge | node | 無法被驅逐的 VMI 數量(evictionStrategy=None) |
kubevirt_vmi_last_connection_timestamp_seconds | Gauge | vmi, namespace | VMI 最後一次連線的時間戳記 |
# 查詢各 phase 的 VMI 分佈
kubevirt_vmi_phase_count
# 查詢特定節點上的 Running VMI 數量
kubevirt_vmi_phase_count{phase="Running", node="worker-1"}
# 查詢不可驅逐的 VMI(可能阻礙節點維護)
kubevirt_vmi_non_evictable > 0CPU 指標
| Metric 名稱 | 類型 | 標籤 | 說明 |
|---|---|---|---|
kubevirt_vmi_vcpu_seconds_total | Counter | vmi, namespace, id, state | vCPU 在各狀態的累計時間(state: run/idle/wait/steal) |
kubevirt_vmi_cpu_usage_seconds_total | Counter | vmi, namespace | VM CPU 總使用時間(user + system) |
kubevirt_vmi_cpu_user_usage_seconds_total | Counter | vmi, namespace | 用戶態 CPU 累計時間 |
kubevirt_vmi_cpu_system_usage_seconds_total | Counter | vmi, namespace | 核心態 CPU 累計時間 |
# 計算 VM CPU 使用率(每分鐘平均)
rate(kubevirt_vmi_cpu_usage_seconds_total[1m])
# 計算 vCPU steal time 比率(過高表示節點 CPU 資源不足)
rate(kubevirt_vmi_vcpu_seconds_total{state="steal"}[5m])
/ on(vmi, namespace)
sum by(vmi, namespace) (rate(kubevirt_vmi_vcpu_seconds_total[5m]))
# 查找 CPU 使用率最高的 VM(Top 10)
topk(10, rate(kubevirt_vmi_cpu_usage_seconds_total[5m]))vCPU State 說明
- run:vCPU 正在執行 guest 指令
- idle:vCPU 空閒(guest 執行 HLT 指令)
- wait:vCPU 等待 I/O 完成
- steal:hypervisor 拿走了原本應給 vCPU 的 host CPU 時間
記憶體指標
| Metric 名稱 | 類型 | 標籤 | 說明 |
|---|---|---|---|
kubevirt_vmi_memory_resident_bytes | Gauge | vmi, namespace, node | 常駐記憶體(RSS),VM 實際佔用的 host 記憶體 |
kubevirt_vmi_memory_available_bytes | Gauge | vmi, namespace | Guest OS 可用記憶體量 |
kubevirt_vmi_memory_balloon_size_bytes | Gauge | vmi, namespace | Balloon driver 當前大小(越大表示 host 回收了越多記憶體) |
kubevirt_vmi_memory_domain_bytes_total | Gauge | vmi, namespace | VM 設定的總記憶體量 |
kubevirt_vmi_memory_pgmajfault | Counter | vmi, namespace | 主要頁面錯誤(major page fault)次數 |
kubevirt_vmi_memory_pgminfault | Counter | vmi, namespace | 次要頁面錯誤(minor page fault)次數 |
kubevirt_vmi_memory_swap_in_traffic_bytes | Counter | vmi, namespace | Swap in 流量(bytes) |
kubevirt_vmi_memory_swap_out_traffic_bytes | Counter | vmi, namespace | Swap out 流量(bytes) |
kubevirt_vmi_memory_used_bytes | Gauge | vmi, namespace | Guest OS 已使用的記憶體量 |
kubevirt_vmi_memory_cached_bytes | Gauge | vmi, namespace | Guest OS 快取使用的記憶體量 |
# 計算 VM 記憶體使用率
kubevirt_vmi_memory_used_bytes / kubevirt_vmi_memory_domain_bytes_total * 100
# 偵測記憶體壓力(swap 活動)
rate(kubevirt_vmi_memory_swap_in_traffic_bytes[5m]) > 0
# 偵測記憶體洩漏(持續增長的 RSS)
deriv(kubevirt_vmi_memory_resident_bytes[1h]) > 0Balloon Memory 監控
kubevirt_vmi_memory_balloon_size_bytes 過大表示 host 正在從 VM 回收記憶體,這可能導致 guest OS 記憶體壓力。應配置告警:
# Prometheus AlertRule 範例
- alert: VMIMemoryPressure
expr: kubevirt_vmi_memory_balloon_size_bytes / kubevirt_vmi_memory_domain_bytes_total > 0.3
for: 5m
labels:
severity: warning
annotations:
summary: "VM {{ $labels.vmi }} 的 balloon 使用率超過 30%,可能存在記憶體壓力"網路指標
| Metric 名稱 | 類型 | 標籤 | 說明 |
|---|---|---|---|
kubevirt_vmi_network_receive_bytes_total | Counter | vmi, namespace, interface | 網路介面接收的總位元組數 |
kubevirt_vmi_network_transmit_bytes_total | Counter | vmi, namespace, interface | 網路介面傳送的總位元組數 |
kubevirt_vmi_network_receive_packets_total | Counter | vmi, namespace, interface | 接收的總封包數 |
kubevirt_vmi_network_transmit_packets_total | Counter | vmi, namespace, interface | 傳送的總封包數 |
kubevirt_vmi_network_receive_errors_total | Counter | vmi, namespace, interface | 接收錯誤數 |
kubevirt_vmi_network_transmit_errors_total | Counter | vmi, namespace, interface | 傳送錯誤數 |
kubevirt_vmi_network_receive_packets_dropped_total | Counter | vmi, namespace, interface | 接收丟包數 |
kubevirt_vmi_network_transmit_packets_dropped_total | Counter | vmi, namespace, interface | 傳送丟包數 |
# 計算 VM 網路頻寬使用率(入向,Mbps)
rate(kubevirt_vmi_network_receive_bytes_total[1m]) * 8 / 1024 / 1024
# 計算丟包率(接收方向)
rate(kubevirt_vmi_network_receive_packets_dropped_total[5m])
/ rate(kubevirt_vmi_network_receive_packets_total[5m]) * 100
# 偵測網路錯誤
rate(kubevirt_vmi_network_receive_errors_total[5m]) > 0
or
rate(kubevirt_vmi_network_transmit_errors_total[5m]) > 0儲存指標
| Metric 名稱 | 類型 | 標籤 | 說明 |
|---|---|---|---|
kubevirt_vmi_storage_iops_read_total | Counter | vmi, namespace, drive | 累計讀取 IOPS |
kubevirt_vmi_storage_iops_write_total | Counter | vmi, namespace, drive | 累計寫入 IOPS |
kubevirt_vmi_storage_read_traffic_bytes_total | Counter | vmi, namespace, drive | 累計讀取位元組數 |
kubevirt_vmi_storage_write_traffic_bytes_total | Counter | vmi, namespace, drive | 累計寫入位元組數 |
kubevirt_vmi_storage_read_times_seconds_total | Counter | vmi, namespace, drive | 讀取操作總延遲(秒) |
kubevirt_vmi_storage_write_times_seconds_total | Counter | vmi, namespace, drive | 寫入操作總延遲(秒) |
kubevirt_vmi_storage_flush_requests_total | Counter | vmi, namespace, drive | Flush 請求次數 |
kubevirt_vmi_storage_flush_times_seconds_total | Counter | vmi, namespace, drive | Flush 操作總延遲(秒) |
# 計算平均讀取 IOPS
rate(kubevirt_vmi_storage_iops_read_total[1m])
# 計算平均讀取延遲(毫秒)
rate(kubevirt_vmi_storage_read_times_seconds_total[5m])
/ rate(kubevirt_vmi_storage_iops_read_total[5m]) * 1000
# 計算磁碟吞吐量(MB/s)
(rate(kubevirt_vmi_storage_read_traffic_bytes_total[1m])
+ rate(kubevirt_vmi_storage_write_traffic_bytes_total[1m])) / 1024 / 1024Migration 指標
| Metric 名稱 | 類型 | 標籤 | 說明 |
|---|---|---|---|
kubevirt_vmi_migration_data_bytes | Gauge | vmi, namespace | Migration 已傳輸的資料量(bytes) |
kubevirt_vmi_migration_data_processed | Gauge | vmi, namespace | 已處理的 dirty 頁面資料量 |
kubevirt_vmi_migration_dirty_memory_rate | Gauge | vmi, namespace | 當前 dirty memory 產生速率(bytes/s) |
kubevirt_vmi_migration_transfer_rate | Gauge | vmi, namespace | 當前實際傳輸速率(bytes/s) |
kubevirt_vmi_migrations_in_pending_phase | Gauge | vmi, namespace | 處於 pending 狀態的 migration 數量 |
kubevirt_vmi_migrations_in_scheduling_phase | Gauge | vmi, namespace | 處於 scheduling 狀態的 migration 數量 |
kubevirt_vmi_migrations_in_running_phase | Gauge | vmi, namespace | 處於 running 狀態的 migration 數量 |
kubevirt_vmi_migration_succeeded | Counter | vmi, namespace | 歷史成功 migration 總數 |
kubevirt_vmi_migration_failed | Counter | vmi, namespace | 歷史失敗 migration 總數 |
# 判斷 migration 是否能收斂(正數表示收斂中)
kubevirt_vmi_migration_transfer_rate - kubevirt_vmi_migration_dirty_memory_rate
# Migration 失敗率
rate(kubevirt_vmi_migration_failed[1h])
/ (rate(kubevirt_vmi_migration_succeeded[1h]) + rate(kubevirt_vmi_migration_failed[1h])) * 100
# 目前正在進行的 migration 總數
sum(kubevirt_vmi_migrations_in_running_phase)系統狀態指標
| Metric 名稱 | 類型 | 說明 |
|---|---|---|
kubevirt_virt_controller_leading | Gauge | virt-controller 是否是當前 leader(1=是,0=否) |
kubevirt_virt_controller_ready | Gauge | virt-controller 就緒狀態 |
kubevirt_virt_operator_leading | Gauge | virt-operator 是否是當前 leader |
kubevirt_virt_operator_ready | Gauge | virt-operator 就緒狀態 |
kubevirt_virt_handler_up | Gauge | 各節點 virt-handler 的存活狀態(標籤含節點名稱) |
kubevirt_allocatable_nodes | Gauge | 可分配 VM 的節點數量 |
kubevirt_nodes_with_kvm | Gauge | 有 KVM 支援的節點數量 |
# 告警:virt-handler 不健康
kubevirt_virt_handler_up == 0
# 告警:沒有 leading controller
sum(kubevirt_virt_controller_leading) == 0
# 監控可用節點數量
kubevirt_allocatable_nodesServiceMonitor 設定說明
KubeVirt 安裝後會自動建立 Service,但需要手動建立(或確認已存在)ServiceMonitor 讓 Prometheus Operator 抓取指標。
完整 ServiceMonitor YAML
# KubeVirt 元件的 ServiceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: kubevirt-servicemonitor
namespace: kubevirt
labels:
# 需要與 Prometheus CR 的 serviceMonitorSelector 匹配
prometheus: kube-prometheus
spec:
selector:
matchLabels:
prometheus.kubevirt.io: "" # KubeVirt service 的預設 label
namespaceSelector:
matchNames:
- kubevirt
endpoints:
- port: metrics
interval: 30s
scheme: https
tlsConfig:
# KubeVirt metrics endpoint 使用 TLS
insecureSkipVerify: true
honorLabels: true
---
# 也需要監控 virt-handler(DaemonSet,在各 worker node)
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: kubevirt-handler-servicemonitor
namespace: kubevirt
labels:
prometheus: kube-prometheus
spec:
selector:
matchLabels:
kubevirt.io: virt-handler
namespaceSelector:
matchNames:
- kubevirt
endpoints:
- port: metrics
interval: 15s # virt-handler 含 VMI 指標,建議較短間隔
scheme: https
tlsConfig:
insecureSkipVerify: true確認 Metrics Endpoint 可存取
# 確認 KubeVirt services 存在
kubectl get svc -n kubevirt
# 測試 metrics endpoint(透過 port-forward)
kubectl port-forward -n kubevirt svc/kubevirt-prometheus-metrics 8443:443 &
curl -k https://localhost:8443/metrics | grep kubevirt | head -20Prometheus RBAC 設定
# 確保 Prometheus 有權限抓取 KubeVirt metrics
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-kubevirt
rules:
- apiGroups: [""]
resources: ["services", "endpoints", "pods"]
verbs: ["get", "list", "watch"]
- apiGroups: ["kubevirt.io"]
resources: ["*"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus-kubevirt
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus-kubevirt
subjects:
- kind: ServiceAccount
name: prometheus-k8s
namespace: monitoring常用 Grafana Dashboard 建議
官方 KubeVirt Grafana Dashboard
KubeVirt 社群提供了官方 Grafana Dashboard,可直接從 Grafana.com 匯入:
| Dashboard | ID | 說明 |
|---|---|---|
| KubeVirt Overview | 11116 | VM 總覽,含數量、狀態分佈 |
| KubeVirt VMI Details | 11117 | 單一 VMI 的詳細指標 |
| KubeVirt Migration | 11118 | Migration 監控專用 |
# 透過 Grafana API 匯入 Dashboard
curl -X POST \
http://admin:password@grafana:3000/api/dashboards/import \
-H 'Content-Type: application/json' \
-d '{"dashboard": {"id": null}, "folderId": 0, "overwrite": true, "inputs": [{"name": "DS_PROMETHEUS", "type": "datasource", "pluginId": "prometheus", "value": "Prometheus"}], "url": "https://grafana.com/api/dashboards/11116/revisions/latest/download"}'建議的告警規則
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: kubevirt-alerts
namespace: kubevirt
labels:
prometheus: kube-prometheus
role: alert-rules
spec:
groups:
- name: kubevirt.rules
rules:
# virt-handler 不健康
- alert: KubeVirtVirtHandlerDown
expr: kubevirt_virt_handler_up == 0
for: 5m
labels:
severity: critical
annotations:
summary: "節點 {{ $labels.node }} 的 virt-handler 不健康"
description: "virt-handler 已停止工作超過 5 分鐘,該節點上的 VM 可能受影響"
# Migration 失敗率過高
- alert: KubeVirtMigrationHighFailureRate
expr: |
rate(kubevirt_vmi_migration_failed[1h]) > 0.1
for: 10m
labels:
severity: warning
annotations:
summary: "Migration 失敗率過高"
description: "每小時 migration 失敗數超過 0.1,請檢查 migration 設定和網路狀況"
# VM 記憶體壓力
- alert: KubeVirtVMIHighMemoryUsage
expr: |
kubevirt_vmi_memory_used_bytes / kubevirt_vmi_memory_domain_bytes_total > 0.9
for: 10m
labels:
severity: warning
annotations:
summary: "VM {{ $labels.vmi }} 記憶體使用率超過 90%"
# vCPU steal time 過高
- alert: KubeVirtHighVCPUStealTime
expr: |
rate(kubevirt_vmi_vcpu_seconds_total{state="steal"}[5m])
/ on(vmi, namespace) group_left()
sum by(vmi, namespace) (rate(kubevirt_vmi_vcpu_seconds_total[5m])) > 0.1
for: 5m
labels:
severity: warning
annotations:
summary: "VM {{ $labels.vmi }} 的 vCPU steal time 超過 10%,節點 CPU 資源可能不足"
# 磁碟寫入延遲過高
- alert: KubeVirtHighStorageWriteLatency
expr: |
rate(kubevirt_vmi_storage_write_times_seconds_total[5m])
/ rate(kubevirt_vmi_storage_iops_write_total[5m]) > 0.1
for: 5m
labels:
severity: warning
annotations:
summary: "VM {{ $labels.vmi }} 磁碟 {{ $labels.drive }} 寫入延遲超過 100ms"
# 沒有 running 的 virt-controller
- alert: KubeVirtNoLeaderController
expr: sum(kubevirt_virt_controller_leading) == 0
for: 1m
labels:
severity: critical
annotations:
summary: "沒有 leading virt-controller,KubeVirt 控制面失效"日誌排查指南
KubeVirt 由多個元件組成,每個元件都有其特定的日誌位置和常見問題模式。
元件日誌架構圖
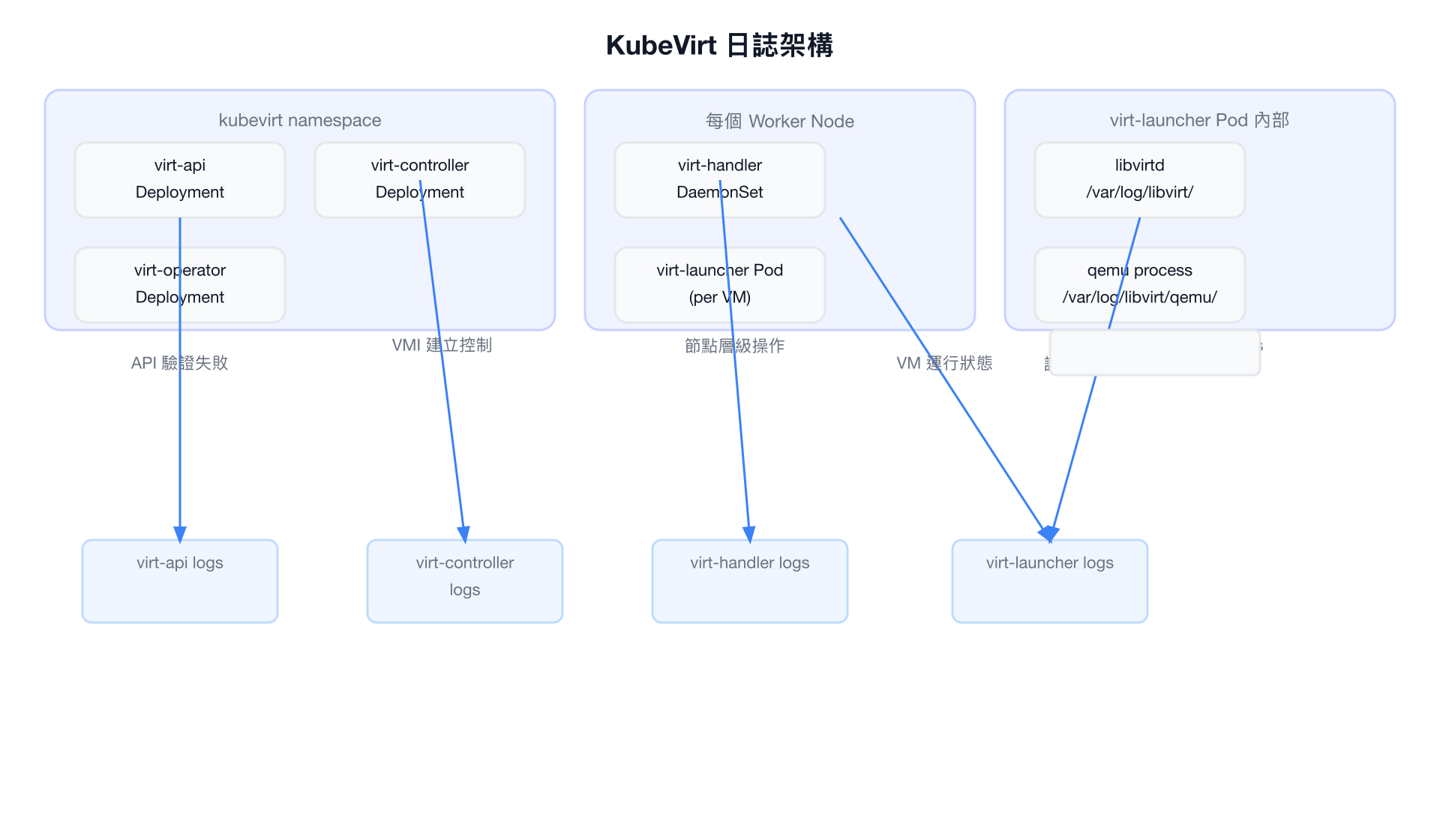
virt-api 日誌
負責:處理所有 KubeVirt API 請求(Admission Webhooks、VM/VMI CRUD)
# 查看 virt-api 日誌
kubectl logs -n kubevirt deployment/virt-api --tail=100
# 持續追蹤
kubectl logs -n kubevirt deployment/virt-api -f
# 只看錯誤
kubectl logs -n kubevirt deployment/virt-api --tail=500 | grep -i "error\|warn\|fail"
# 查看 webhook 相關日誌
kubectl logs -n kubevirt deployment/virt-api | grep -i "webhook\|validat\|mutate"常見錯誤類型:
| 錯誤關鍵字 | 可能原因 | 解決方式 |
|---|---|---|
webhook: denied the request | VM spec 驗證失敗 | 檢查 VM spec 是否符合規範 |
certificate | TLS 憑證過期或錯誤 | 更新 webhook 憑證 |
connection refused | virt-api 未就緒 | 重啟 virt-api pod |
unauthorized | RBAC 設定錯誤 | 確認 ServiceAccount 權限 |
virt-controller 日誌
負責:VMI 生命週期管理、Migration 協調、DataVolume 整合
# 查看 virt-controller 日誌
kubectl logs -n kubevirt deployment/virt-controller --tail=200
# 過濾 migration 相關日誌
kubectl logs -n kubevirt deployment/virt-controller | grep -i "migration"
# 過濾特定 VMI 的日誌
kubectl logs -n kubevirt deployment/virt-controller | grep "my-vm"
# 查看 leader election 狀態
kubectl logs -n kubevirt deployment/virt-controller | grep -i "leader"常見錯誤類型:
| 錯誤關鍵字 | 可能原因 | 解決方式 |
|---|---|---|
failed to create virt-launcher | 節點資源不足或 taint 問題 | 檢查節點狀態和 tolerations |
migration failed | Migration 超時或網路問題 | 查看 VMIM events |
DataVolume not ready | CDI/DataVolume 問題 | 檢查 DataVolume 狀態 |
failed to schedule | 無可用節點 | 檢查節點資源和 selector |
virt-handler 日誌
負責:節點層級的 VMI 管理,包括網路設定、磁碟掛載、QEMU 程序管理
# 查看特定節點的 virt-handler 日誌
NODE="worker-1"
kubectl logs -n kubevirt daemonset/virt-handler \
--tail=200 \
$(kubectl get pod -n kubevirt -l kubevirt.io=virt-handler \
-o jsonpath="{.items[?(@.spec.nodeName=='${NODE}')].metadata.name}")
# 查看所有節點的 virt-handler(可能有大量輸出)
kubectl logs -n kubevirt daemonset/virt-handler --tail=50
# 過濾網路相關錯誤
kubectl logs -n kubevirt daemonset/virt-handler | grep -i "network\|multus\|bridge\|vlan"
# 過濾磁碟相關錯誤
kubectl logs -n kubevirt daemonset/virt-handler | grep -i "disk\|volume\|mount\|pvc"常見錯誤類型:
| 錯誤關鍵字 | 可能原因 | 解決方式 |
|---|---|---|
network plugin | Multus/CNI 設定錯誤 | 確認 NetworkAttachmentDefinition |
failed to mount volume | PVC 不可用或格式問題 | 檢查 PVC 狀態和存取模式 |
KVM not available | 節點無 KVM 支援 | 確認節點 KVM 模組已載入 |
failed to configure interface | 網路橋接設定失敗 | 檢查節點網路設定 |
virt-launcher 日誌
負責:管理單個 VMI 的完整生命週期,包含 libvirt 和 QEMU 程序
# 找到對應 VMI 的 virt-launcher pod
VMI_NAME="my-vm"
NAMESPACE="default"
kubectl get pod -n ${NAMESPACE} -l "kubevirt.io/created-by" | grep ${VMI_NAME}
# 查看 virt-launcher 日誌(launcher process)
kubectl logs -n ${NAMESPACE} virt-launcher-${VMI_NAME}-xxxxx
# 查看 libvirt 日誌(在 pod 內)
kubectl exec -n ${NAMESPACE} virt-launcher-${VMI_NAME}-xxxxx \
-- cat /var/log/libvirt/libvirtd.log
# 查看 QEMU 日誌
kubectl exec -n ${NAMESPACE} virt-launcher-${VMI_NAME}-xxxxx \
-- ls /var/log/libvirt/qemu/
kubectl exec -n ${NAMESPACE} virt-launcher-${VMI_NAME}-xxxxx \
-- cat /var/log/libvirt/qemu/${VMI_NAME}.log
# 進入 virt-launcher pod 進行深入排查
kubectl exec -it -n ${NAMESPACE} virt-launcher-${VMI_NAME}-xxxxx -- bashvirt-launcher 雙程序架構
每個 virt-launcher pod 包含兩個主要程序:
- launcher:監控程序,負責啟動和監控 libvirtd/QEMU
- libvirtd:libvirt daemon,管理 QEMU VM
QEMU 本身是 libvirtd 的子程序。若 VM crash,查看順序應為:virt-launcher logs → libvirt logs → QEMU logs
virtctl adm logverbosity 使用
virtctl adm logverbosity 命令可以在不重啟任何 KubeVirt 元件的情況下,動態調整各元件的日誌詳細程度。
日誌 Level 說明
| Level | 說明 | 適用場景 |
|---|---|---|
0 | 最少日誌,只有嚴重錯誤 | 生產環境(降低 I/O) |
1 | 預設 level,一般資訊 | 正常運維 |
2 | 更詳細的操作日誌 | 輕度排查 |
3-4 | 詳細的狀態變更日誌 | 深入排查 |
5-7 | 更多 debug 資訊 | 開發測試 |
8-9 | 最詳細的 debug 日誌 | 深度除錯 |
動態調整指令
# 查看目前的 log level
virtctl adm logverbosity
# 設定所有元件的 log level 為 4(verbose)
virtctl adm logverbosity --all 4
# 只調整特定元件
virtctl adm logverbosity --virt-api 3
virtctl adm logverbosity --virt-controller 4
virtctl adm logverbosity --virt-handler 4
virtctl adm logverbosity --virt-launcher 4
# 排查特定問題時提升 level
virtctl adm logverbosity --virt-handler 6
# ... 重現問題 ...
# 排查完畢後恢復
virtctl adm logverbosity --virt-handler 2
# 使用 virtctl 查看特定 VMI 的詳細 log
virtctl adm logverbosity --virt-launcher 9何時調高 Log Level
建議在以下情況下暫時提高 log level:
- VM 建立失敗(
virt-handler: 5,virt-launcher: 5) - Migration 失敗(
virt-controller: 4,virt-handler: 5) - 網路問題(
virt-handler: 6) - 效能問題(
virt-launcher: 4)
記得在問題排查完畢後恢復到正常 level,高 log level 會產生大量日誌,消耗 I/O 資源。
Guest OS 監控
Downward Metrics Volume
KubeVirt 提供了一個特殊的 volume 類型,讓 guest OS 可以讀取 Kubernetes 層面的 metrics:
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: my-vm-with-metrics
spec:
template:
spec:
domain:
devices:
disks:
- name: downwardmetrics
disk:
bus: virtio
volumes:
- name: downwardmetrics
downwardMetrics: {} # 啟用 downward metricsGuest OS 掛載後可以讀取:
# 在 guest OS 內(Linux)
mount /dev/vdb /mnt/metrics
cat /mnt/metrics/metrics可以讀取到的指標包括:CPU 使用率、記憶體使用量、節點名稱等 Kubernetes 層面的資訊。
qemu-guest-agent 提供的監控能力
# 從 host 端(透過 virtctl)查詢 guest 資訊
virtctl guestosinfo my-vm # 查看 guest OS 資訊
virtctl fslist my-vm # 查看 guest 中的文件系統
virtctl userlist my-vm # 查看登入的使用者Node Exporter 在 VM 內的使用
對於需要細粒度 guest OS 監控的場景,最完整的方式是在 VM 內安裝 node_exporter:
# cloud-init 自動安裝 node_exporter
volumes:
- name: cloudinit
cloudInitNoCloud:
userData: |
#cloud-config
packages:
- wget
runcmd:
- |
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
tar -xzf node_exporter-*.tar.gz
mv node_exporter-*/node_exporter /usr/local/bin/
- systemctl enable --now node-exporter
write_files:
- path: /etc/systemd/system/node-exporter.service
content: |
[Unit]
Description=Node Exporter
[Service]
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.targetGuest 監控的最佳選擇
根據監控需求選擇適合的方式:
| 方式 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| KubeVirt virt-handler metrics | 無需修改 VM、統一管理 | 只有 hypervisor 層面的資料 | 所有 VM 的基礎監控 |
| Downward Metrics | 讓 guest 知道 K8s 資訊 | 功能有限 | Guest 需要感知 K8s 環境 |
| node_exporter in VM | 完整的 OS 指標 | 每個 VM 需要安裝和維護 | 需要細粒度 OS 監控的 VM |
| qemu-guest-agent | 豐富的 guest 資訊 | 需要安裝 agent | 需要即時 guest 狀態的場景 |
常用 kubectl 診斷指令集合
快速狀態總覽
# 查看所有 VMI 狀態(跨 namespace)
kubectl get vmi -A
# 查看所有 VMI 的詳細資訊(包含 IP、節點)
kubectl get vmi -A -o wide
# 按 phase 統計 VMI 數量
kubectl get vmi -A -o jsonpath='{.items[*].status.phase}' | tr ' ' '\n' | sort | uniq -c
# 查看所有 VM(包含停止的)
kubectl get vm -A特定 VMI 診斷
# 查看 VMI 完整狀態
kubectl describe vmi <vmi-name> -n <namespace>
# 查看 VMI 的所有 conditions
kubectl get vmi <vmi-name> -n <namespace> \
-o jsonpath='{.status.conditions}' | jq .
# 查看 VMI 的 IP 地址
kubectl get vmi <vmi-name> -n <namespace> \
-o jsonpath='{.status.interfaces[*].ipAddress}'
# 確認 VMI 是否可以 migrate
kubectl get vmi <vmi-name> -n <namespace> \
-o jsonpath='{.status.conditions[?(@.type=="IsMigratable")]}'
# 查看 VMI 目前所在節點
kubectl get vmi <vmi-name> -n <namespace> \
-o jsonpath='{.status.nodeName}'查看 Events
# 查看特定 VMI 的 events
kubectl get events -n <namespace> \
--field-selector involvedObject.name=<vmi-name> \
--sort-by=.lastTimestamp
# 查看最近的 KubeVirt 相關 events
kubectl get events -A \
--sort-by=.lastTimestamp \
| grep -i "kubevirt\|virt\|vm" \
| tail -30
# 查看 Warning 類型的 events
kubectl get events -A --field-selector type=Warning | grep -i "vm\|virt"查看 virt-launcher Pod Logs
# 找到對應 VMI 的 virt-launcher pod
kubectl get pod -n <namespace> \
-l "kubevirt.io/created-by" \
-o custom-columns='NAME:.metadata.name,VMI:.metadata.labels.kubevirt\.io/domain,NODE:.spec.nodeName'
# 查看 virt-launcher logs
kubectl logs -n <namespace> <virt-launcher-pod-name>
# 查看 previous container 的 logs(若 pod 重啟過)
kubectl logs -n <namespace> <virt-launcher-pod-name> --previous
# 進入 virt-launcher 執行診斷指令
kubectl exec -it -n <namespace> <virt-launcher-pod-name> -- bash
# 在 pod 內查看 libvirt 連線
virsh list --all
virsh dominfo <vmi-name>
virsh dumpxml <vmi-name>查看 KubeVirt CR 狀態
# 查看 KubeVirt 部署狀態
kubectl get kubevirt -n kubevirt
kubectl describe kubevirt kubevirt -n kubevirt
# 查看 KubeVirt 版本和設定
kubectl get kubevirt kubevirt -n kubevirt \
-o jsonpath='{.status.observedKubeVirtVersion}'
# 查看 operator 狀態
kubectl get pod -n kubevirt -l kubevirt.io=virt-operator
# 查看所有 KubeVirt 元件狀態
kubectl get pod -n kubevirt -o wideMigration 問題診斷
# 查看所有 migration
kubectl get vmim -A
# 查看失敗的 migration
kubectl get vmim -A \
-o jsonpath='{range .items[?(@.status.phase=="Failed")]}{.metadata.namespace}/{.metadata.name}: {.status.migrationState.failureReason}{"\n"}{end}'
# 查看特定 migration 的詳細資訊
kubectl describe vmim <migration-name> -n <namespace>
# 查看 migration 相關的 events
kubectl get events -n <namespace> \
| grep -i "migrat"
# 查看 virt-controller migration 相關日誌
kubectl logs -n kubevirt deployment/virt-controller \
| grep -i "migration" | tail -50完整排查流程(Step-by-Step)
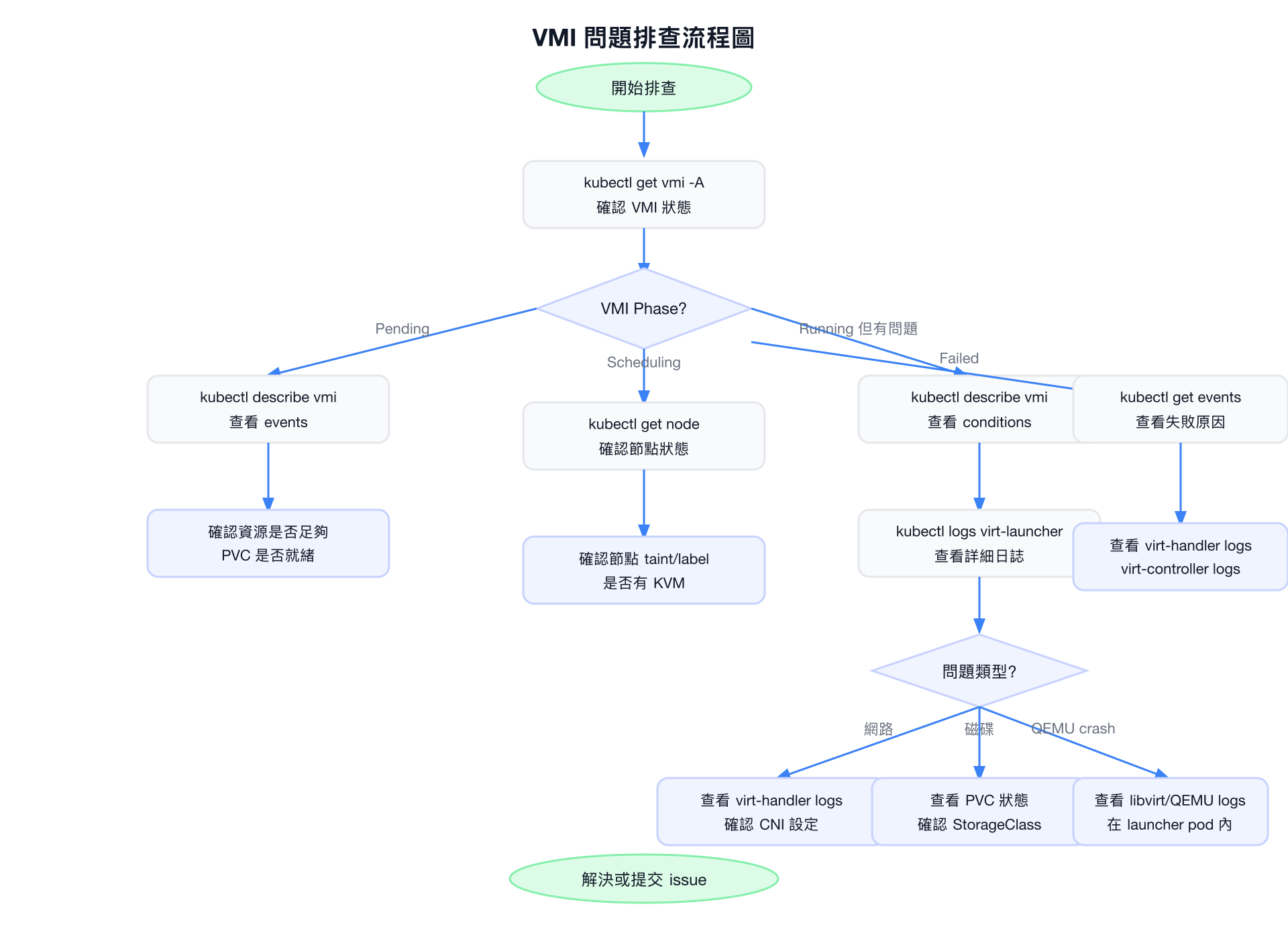
常用的一行診斷指令
# 顯示所有不在 Running phase 的 VMI
kubectl get vmi -A -o json | \
jq '.items[] | select(.status.phase != "Running") | {name: .metadata.name, ns: .metadata.namespace, phase: .status.phase}'
# 找出記憶體配置最大的 VMI Top 5
kubectl get vmi -A -o json | \
jq '.items[] | {name: .metadata.name, memory: .spec.domain.resources.requests.memory}' | \
sort
# 確認所有節點的 virt-handler 是否正常
kubectl get pod -n kubevirt -l kubevirt.io=virt-handler \
-o custom-columns='NODE:.spec.nodeName,STATUS:.status.phase,READY:.status.conditions[?(@.type=="Ready")].status'
# 查看當前正在進行的 migration
kubectl get vmim -A -o json | \
jq '.items[] | select(.status.phase == "Running") | {name: .metadata.name, vmi: .spec.vmiName}'
# 快速健康檢查(一次執行)
echo "=== KubeVirt Components ===" && \
kubectl get pod -n kubevirt && \
echo "" && \
echo "=== VMI Status Summary ===" && \
kubectl get vmi -A && \
echo "" && \
echo "=== Active Migrations ===" && \
kubectl get vmim -A日誌保留與收集建議
在生產環境中,建議設定集中式日誌收集:
- Elasticsearch + Fluentd/Fluent Bit:收集所有 virt-* 元件日誌
- Loki + Promtail:輕量級選擇,與 Grafana 整合良好
- 保留時間:至少保留 30 天的日誌,以便事後排查
特別重要的日誌 label 過濾條件:
namespace="kubevirt" OR label="kubevirt.io=virt-launcher"