GPU/vGPU Passthrough 深入剖析 — 從 VFIO 到 Device Plugin
概述
GPU Passthrough 允許虛擬機直接存取實體 GPU 硬體,繞過 Hypervisor 的模擬層,讓 Guest OS 取得接近原生的 GPU 效能。這對於 AI/ML 訓練推論、圖形渲染、影像編解碼、科學運算等 GPU 密集型工作負載至關重要。
KubeVirt 利用 Linux VFIO(Virtual Function I/O) 框架與 Kubernetes Device Plugin 機制,提供兩種 GPU 虛擬化模式:
| 模式 | 技術基礎 | GPU 共享 | 效能 | 適用場景 |
|---|---|---|---|---|
| GPU 直通(PCI Passthrough) | VFIO + IOMMU | 1 VM : 1 GPU | ★★★★★ 原生效能 | AI 訓練、HPC |
| vGPU(Mediated Devices) | mdev + NVIDIA GRID | N VM : 1 GPU | ★★★★☆ 接近原生 | VDI、推論、多租戶 |
VMware 使用者須知
在 VMware 環境中,GPU 直通對應 DirectPath I/O,vGPU 則對應 NVIDIA GRID vGPU Profile 的設定方式。KubeVirt 的做法在概念上相同,但透過宣告式的 YAML 設定取代了 vCenter GUI 操作,並利用 Kubernetes 原生的資源排程機制進行裝置分配。
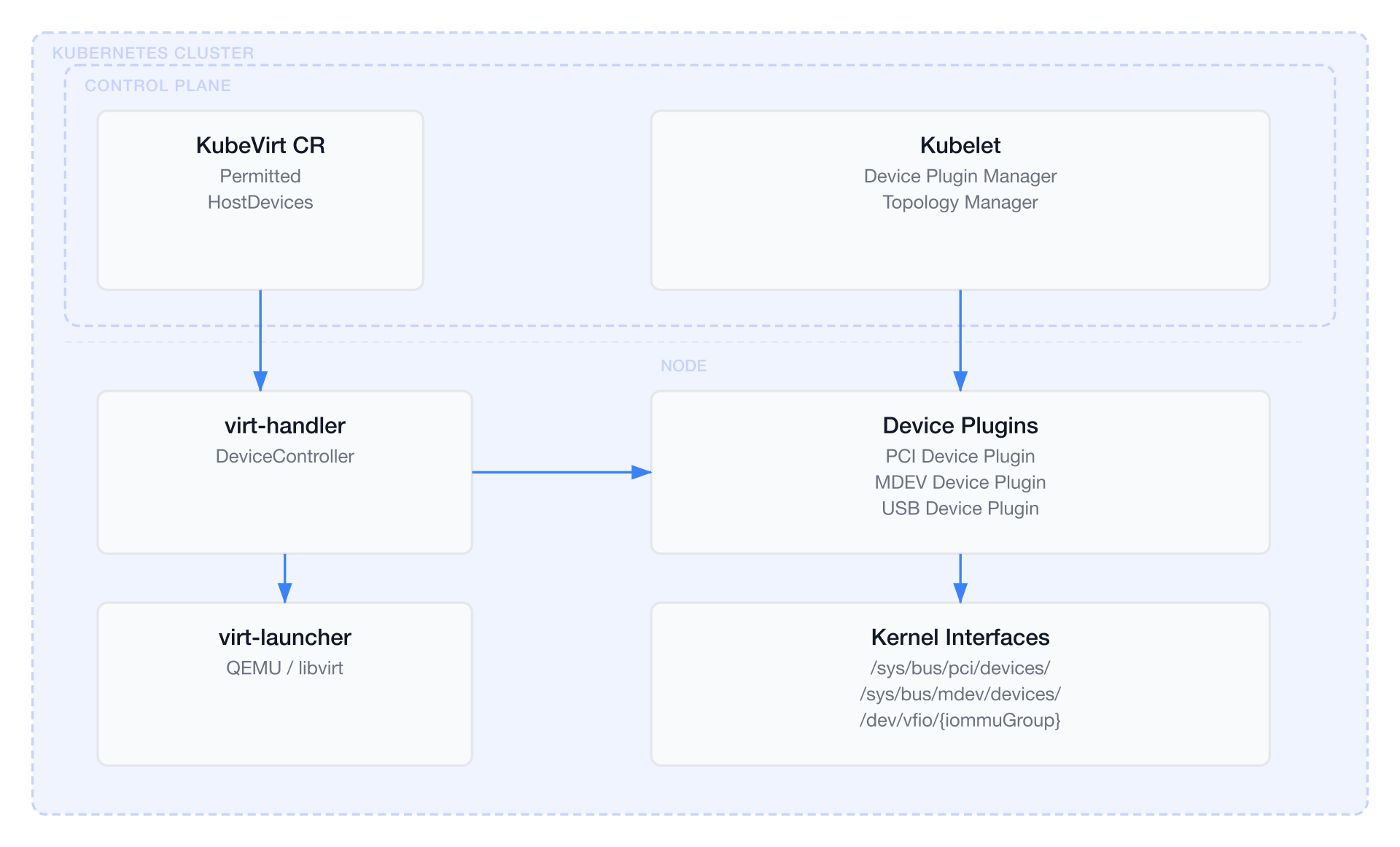
架構總覽
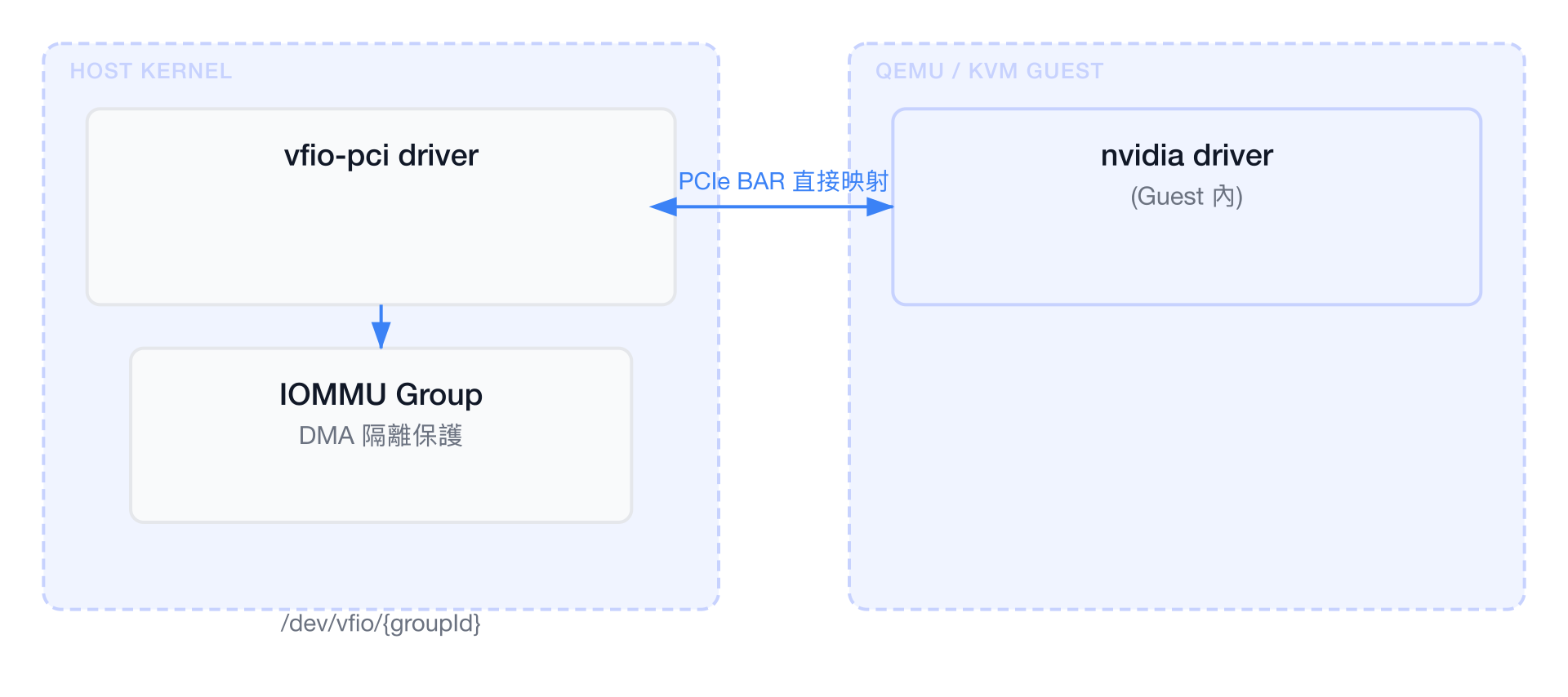
GPU 直通(PCI Passthrough)
VFIO 框架原理
VFIO(Virtual Function I/O)是 Linux 核心提供的使用者空間裝置驅動框架。它透過 IOMMU(Input-Output Memory Management Unit)實現安全的裝置直通,確保虛擬機只能存取被分配的裝置記憶體區域,無法越界存取主機或其他 VM 的記憶體。
DeviceHandler 介面
KubeVirt 的 DeviceHandler 介面(定義於 pkg/virt-handler/device-manager/common.go)負責讀取 PCI 裝置的底層資訊:
type DeviceHandler interface {
// GetDeviceIOMMUGroup 從 sysfs 讀取裝置的 IOMMU group ID
// 路徑: /sys/bus/pci/devices/{pciAddress}/iommu_group
GetDeviceIOMMUGroup(basepath string, pciAddress string) (string, error)
// GetDeviceDriver 驗證裝置是否綁定至 vfio-pci 驅動
// 路徑: /sys/bus/pci/devices/{pciAddress}/driver
GetDeviceDriver(basepath string, pciAddress string) (string, error)
// GetDeviceNumaNode 讀取裝置的 NUMA 節點親和性
// 路徑: /sys/bus/pci/devices/{pciAddress}/numa_node
GetDeviceNumaNode(basepath string, pciAddress string) (int, error)
// GetDevicePCIID 讀取 vendor:device ID(如 "10DE:1DB6")
// 路徑: /sys/bus/pci/devices/{pciAddress}/vendor, /sys/bus/pci/devices/{pciAddress}/device
GetDevicePCIID(basepath string, pciAddress string) (string, error)
}PCI Device Plugin 運作流程
PCI Device Plugin(pci_device.go)負責探索節點上的 GPU 裝置並向 Kubelet 註冊:
1. 裝置探索:
Plugin 遍歷 /sys/bus/pci/devices 目錄,根據 KubeVirt CR 中設定的 pciVendorSelector(格式為 vendor:device,如 10DE:1DB6)過濾匹配的 PCI 裝置。每個匹配的裝置必須已綁定至 vfio-pci 驅動。
2. PCIDevice 資料結構:
type PCIDevice struct {
pciID string // vendor:device ID,如 "10DE:1DB6"
driver string // 目前綁定的驅動程式,必須為 "vfio-pci"
pciAddress string // BDF 格式位址,如 "0000:3b:00.0"
iommuGroup string // IOMMU group 編號
numaNode int // 所屬的 NUMA 節點
}3. 裝置分配(Allocate):
當 Kubelet 呼叫 Allocate() gRPC 方法時,Plugin 回傳以下資源:
- 環境變數:
PCI_RESOURCE_{resourceName}— 包含分配的 PCI 位址(逗號分隔) - 裝置節點:
/dev/vfio/vfio— VFIO 容器裝置(所有 VFIO 裝置共用)/dev/vfio/{iommuGroupId}— 特定 IOMMU group 的裝置檔案
IOMMU Group 限制
同一 IOMMU group 中的所有裝置必須一起直通給同一個 VM。這是硬體層級的限制——IOMMU 以 group 為單位進行 DMA 隔離。若 GPU 與其他裝置(如 PCIe bridge)共用同一個 IOMMU group,則這些裝置都必須被直通。可使用 ACS(Access Control Services)來分割 IOMMU group。
Libvirt XML 生成
KubeVirt 將 PCI 裝置資訊轉換為 libvirt 可理解的 XML 格式:
<hostdev type='pci' managed='no'>
<driver name='vfio'/>
<source>
<address domain='0x0000' bus='0x3b' slot='0x00' function='0x0'/>
</source>
<alias name='gpu-gpu1'/>
</hostdev>其中 managed='no' 表示由 KubeVirt(而非 libvirt)管理驅動程式的綁定與解綁。PCI 位址的 domain、bus、slot、function 從 BDF 格式位址解析而來。
vGPU 支援(Mediated Devices)
mdev 框架簡介
Mediated Devices(mdev)是 Linux 核心的裝置虛擬化框架,允許單一實體裝置被分割成多個虛擬裝置實例。NVIDIA vGPU 利用此框架將一張實體 GPU 分割為多個 vGPU Profile,每個 Profile 具有固定的顯存大小和運算能力配額。
Physical GPU (Tesla T4, 16GB)
├── GRID T4-1Q (1GB VRAM × 16 instances)
├── GRID T4-2Q (2GB VRAM × 8 instances)
├── GRID T4-4Q (4GB VRAM × 4 instances)
├── GRID T4-8Q (8GB VRAM × 2 instances)
└── GRID T4-16Q (16GB VRAM × 1 instance)關鍵 sysfs 路徑
mdev 框架透過 sysfs 檔案系統提供管理介面:
| 路徑 | 用途 |
|---|---|
/sys/class/mdev_bus/{parentId}/mdev_supported_types/ | 列出支援的 vGPU 類型 |
.../mdev_supported_types/{typeId}/name | vGPU 類型名稱(如 "GRID T4-1Q") |
.../mdev_supported_types/{typeId}/available_instances | 剩餘可建立的實例數 |
.../mdev_supported_types/{typeId}/create | 寫入 UUID 以建立新的 mdev 實例 |
/sys/bus/mdev/devices/{uuid}/remove | 寫入 "1" 以移除 mdev 實例 |
/sys/bus/mdev/devices/{uuid}/iommu_group | 該 mdev 實例的 IOMMU group |
MDEVTypesManager
KubeVirt 使用 MDEVTypesManager 結構體管理 mdev 類型的建立與生命週期。此元件負責:
- 類型探索:掃描所有 mdev bus 上的父裝置,讀取
mdev_supported_types以取得可用的 vGPU Profile - 實例建立:根據 KubeVirt CR 的
mediatedDevices設定,為匹配的類型建立適當數量的 mdev 實例 - 實例清理:移除不再需要的 mdev 實例
MDEV Device Plugin 運作流程
1. MDEV 資料結構:
type MDEV struct {
UUID string // mdev 實例的唯一識別碼
typeName string // vGPU 類型名稱,如 "GRID T4-1Q"
parentPciAddress string // 父 GPU 的 PCI 位址
iommuGroup string // IOMMU group 編號
numaNode int // 所屬 NUMA 節點(繼承自父 GPU)
}2. 裝置探索:
MediatedDevicePlugin 讀取 /sys/bus/mdev/devices 目錄,根據 KubeVirt CR 中的 mdevNameSelector(如 "GRID T4-1Q")過濾匹配的 mdev 實例。
3. 裝置分配(Allocate):
- 環境變數:
MDEV_PCI_RESOURCE_{resourceName}— 包含分配的 mdev UUID(逗號分隔) - 裝置節點:與 PCI passthrough 相同,提供
/dev/vfio/vfio和對應的 IOMMU group 裝置
4. 公平排程(Ring-based Allocation):
為了將 vGPU 實例均勻分佈在多張實體 GPU 上,KubeVirt 採用 ring-based 分配策略。Device Plugin 會追蹤每張父 GPU 上已分配的 mdev 實例數量,優先從負載較低的父 GPU 上分配新實例,避免「熱點」集中在單一 GPU 上。
Libvirt XML 生成
vGPU 裝置在 libvirt XML 中以 mdev hostdev 形式呈現:
<hostdev type='mdev' mode='subsystem' model='vfio-pci'>
<source>
<address uuid='a]297db4-f744-439f-98b3-80f816d9e8f9'/>
</source>
<alias name='gpu-vgpu1'/>
</hostdev>VGPUOptions 支援
KubeVirt 支援 vGPU 的顯示輸出選項,用於遠端桌面(VDI)場景:
- display.enabled:啟用 vGPU 的虛擬顯示輸出
- display.ramFB.enabled:啟用 RAM FrameBuffer,提供開機畫面與 BIOS 畫面的顯示輸出
這些選項會轉換為 libvirt XML 中的 <graphics> 與 <video> 設定,允許透過 VNC 或 SPICE 協定存取 vGPU 的顯示輸出。
裝置外掛架構(Device Plugin Architecture)
DeviceController 架構
DeviceController 是 virt-handler 中管理所有 Device Plugin 的核心結構。它區分兩類外掛:
永久外掛(Permanent Plugins):
這些外掛在 virt-handler 啟動時即自動註冊,不需要額外設定:
| 外掛 | 資源名稱 | 用途 |
|---|---|---|
| KVM | devices.kubevirt.io/kvm | /dev/kvm 裝置存取 |
| TUN | devices.kubevirt.io/tun | /dev/net/tun 網路裝置 |
| vhost-net | devices.kubevirt.io/vhost-net | vhost-net 加速 |
動態外掛(Dynamic Plugins):
這些外掛根據 KubeVirt CR 中 PermittedHostDevices 的設定動態建立與銷毀:
| 外掛 | 資源名稱格式 | 觸發條件 |
|---|---|---|
| PCI Device Plugin | kubevirt.io/{resourceName} | 設定 pciHostDevices |
| MDEV Device Plugin | kubevirt.io/{resourceName} | 設定 mediatedDevices |
| USB Device Plugin | kubevirt.io/{resourceName} | 設定 usbHostDevices |
Device Plugin gRPC 介面
DevicePluginBase 實作了 Kubernetes Device Plugin 的 gRPC 介面:
// ListAndWatch 持續向 Kubelet 回報可用裝置清單
func (dp *DevicePluginBase) ListAndWatch(e *pluginapi.Empty,
s pluginapi.DevicePlugin_ListAndWatchServer) error
// Allocate 當 Pod 請求裝置時,回傳裝置存取所需的環境變數與裝置節點
func (dp *DevicePluginBase) Allocate(ctx context.Context,
r *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error)每個 Device Plugin 都會在 Kubelet 的裝置外掛目錄下建立 Unix socket:
/var/lib/kubelet/device-plugins/kubevirt-{suffix}.sock裝置生命週期
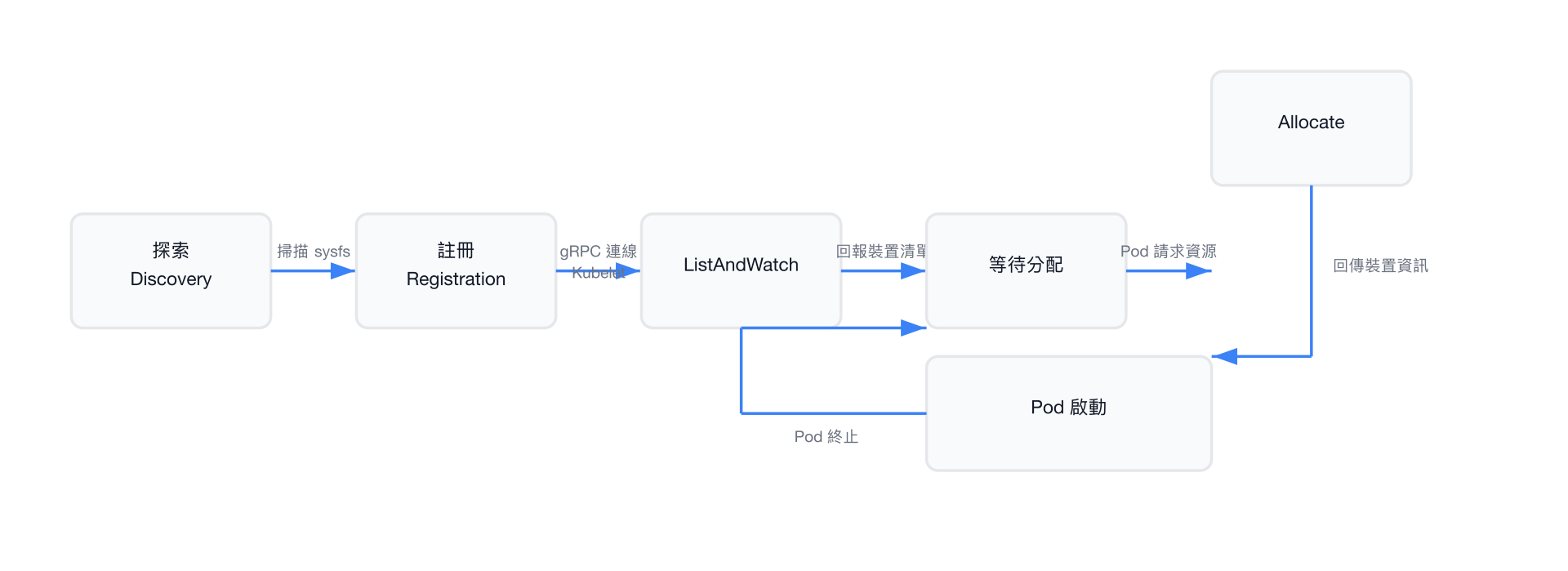
- 探索(Discovery):掃描
/sys/bus/pci/devices或/sys/bus/mdev/devices,收集匹配的裝置 - 註冊(Registration):向 Kubelet 的 Device Plugin Manager 註冊,提供資源名稱與 socket 路徑
- ListAndWatch:持續監控裝置狀態變化(新增、移除、健康狀態),即時更新 Kubelet
- Allocate:回傳環境變數、裝置節點路徑與掛載點,供容器使用
PermittedHostDevices 設定
KubeVirt CR 中的 PermittedHostDevices 區段定義了哪些主機裝置可以暴露給虛擬機:
spec:
configuration:
permittedHostDevices:
pciHostDevices:
- pciVendorSelector: "10DE:1DB6" # vendor:device ID
resourceName: "nvidia.com/Tesla_V100"
externalResourceProvider: false # 由 KubeVirt 管理
mediatedDevices:
- mdevNameSelector: "GRID T4-1Q" # mdev 類型名稱
resourceName: "nvidia.com/GRID_T4-1Q"
externalResourceProvider: false外部資源提供者
當 externalResourceProvider: true 時,KubeVirt 不會建立自己的 Device Plugin,而是期望由外部元件(如 NVIDIA GPU Operator)提供 Device Plugin。這適用於已經有專用 Device Plugin 管理 GPU 資源的環境。
YAML 範例
KubeVirt CR 設定(許可裝置)
apiVersion: kubevirt.io/v1
kind: KubeVirt
metadata:
name: kubevirt
namespace: kubevirt
spec:
configuration:
permittedHostDevices:
pciHostDevices:
- pciVendorSelector: "10DE:1DB6"
resourceName: "nvidia.com/Tesla_V100"
- pciVendorSelector: "10DE:20B0"
resourceName: "nvidia.com/A100_40GB"
mediatedDevices:
- mdevNameSelector: "GRID T4-1Q"
resourceName: "nvidia.com/GRID_T4-1Q"
- mdevNameSelector: "GRID A100-4C"
resourceName: "nvidia.com/GRID_A100-4C"VMI — GPU 直通(PCI Passthrough)
apiVersion: kubevirt.io/v1
kind: VirtualMachineInstance
metadata:
name: gpu-vm
labels:
workload: ai-training
spec:
domain:
devices:
gpus:
- name: gpu1
deviceName: nvidia.com/Tesla_V100
disks:
- name: rootdisk
disk:
bus: virtio
interfaces:
- name: default
masquerade: {}
resources:
requests:
memory: "8Gi"
cpu:
cores: 4
dedicatedCPUPlacement: true
numa:
guestMappingPassthrough: {}
memory:
hugepages:
pageSize: "1Gi"
networks:
- name: default
pod: {}
volumes:
- name: rootdisk
containerDisk:
image: registry.example.com/ubuntu-gpu:22.04最佳效能組合
GPU 直通搭配 dedicatedCPUPlacement、hugepages 和 guestMappingPassthrough 可以確保 CPU、記憶體與 GPU 都在同一個 NUMA 節點上,避免跨 NUMA 存取造成的效能損失。
VMI — vGPU(Mediated Device)
apiVersion: kubevirt.io/v1
kind: VirtualMachineInstance
metadata:
name: vgpu-vm
labels:
workload: vdi-desktop
spec:
domain:
devices:
gpus:
- name: vgpu1
deviceName: nvidia.com/GRID_T4-1Q
virtualGPUOptions:
display:
enabled: true
ramFB:
enabled: true
disks:
- name: rootdisk
disk:
bus: virtio
interfaces:
- name: default
masquerade: {}
resources:
requests:
memory: "4Gi"
cpu:
cores: 2
networks:
- name: default
pod: {}
volumes:
- name: rootdisk
containerDisk:
image: registry.example.com/windows11-vdi:latestVMI — 通用 PCI 裝置(hostDevices)
hostDevices 適用於非 GPU 類的 PCI 裝置(FPGA、網路加速卡、NVMe 等):
apiVersion: kubevirt.io/v1
kind: VirtualMachineInstance
metadata:
name: fpga-vm
spec:
domain:
devices:
hostDevices:
- name: fpga1
deviceName: intel.com/FPGA_ARRIA10
- name: nic1
deviceName: intel.com/X710_SRIOV_VF
resources:
requests:
memory: "4Gi"gpus vs hostDevices
gpus 欄位是 hostDevices 的特化版本,額外支援 virtualGPUOptions(如 display、ramFB)。對於純運算用途的 GPU,兩者的效果相同。對於需要顯示輸出的 vGPU,應使用 gpus 欄位。
效能考量
NUMA 親和性
GPU 透過 PCIe 匯流排連接至特定的 CPU socket,因此具有天然的 NUMA 親和性。當 vCPU 與 GPU 不在同一個 NUMA 節點時,所有 GPU 相關的 DMA 傳輸和 MMIO 操作都需要跨越 NUMA 節點,延遲顯著增加。
KubeVirt 的 Device Plugin 透過 TopologyInfo 向 Kubelet 回報每個裝置的 NUMA 節點資訊:
// pci_device.go — 回報裝置拓撲資訊
func (dp *PCIDevicePlugin) topologyForNode(numaNode *int) *pluginapi.TopologyInfo {
if numaNode != nil && *numaNode >= 0 {
return &pluginapi.TopologyInfo{
Nodes: []*pluginapi.NUMANode{
{ID: int64(*numaNode)},
},
}
}
return nil
}Kubelet 的 Topology Manager 會根據此資訊,確保 Pod 的 CPU 和裝置被分配到同一個 NUMA 節點上。
Topology Manager 策略
請確認 Kubelet 配置了適當的 Topology Manager 策略:
single-numa-node:強制所有資源在同一 NUMA 節點(推薦用於 GPU 工作負載)restricted:盡量對齊,無法滿足時拒絕 Podbest-effort:盡量對齊,但不保證none:不進行拓撲對齊(預設)
PCIe 拓撲考量
NUMA Node 0 NUMA Node 1
┌──────────────────┐ ┌──────────────────┐
│ CPU 0 │ │ CPU 1 │
│ ├─ PCIe Root │ │ ├─ PCIe Root │
│ │ ├─ GPU 0 ✓ │ │ │ ├─ GPU 2 │
│ │ └─ GPU 1 ✓ │ │ │ └─ GPU 3 │
│ └─ Memory 64GB │ │ └─ Memory 64GB │
└──────────────────┘ └──────────────────┘
↑ ↑
VM 的 vCPU 分配在此 若 vCPU 分配在 Node 1
GPU 0/1 直通效能最佳 但 GPU 在 Node 0 → 效能損失最佳效能配置建議
spec:
domain:
cpu:
cores: 8
dedicatedCPUPlacement: true # CPU Pinning
isolateEmulatorThread: true # 隔離 QEMU emulator thread
numa:
guestMappingPassthrough: {} # NUMA 拓撲直通
model: host-passthrough # 完整暴露 CPU 特性
memory:
hugepages:
pageSize: "1Gi" # 大頁記憶體
devices:
gpus:
- name: gpu1
deviceName: nvidia.com/Tesla_V100效能陷阱
未啟用 dedicatedCPUPlacement 的 GPU VM 可能面臨 vCPU 在不同 NUMA 節點間遷移的問題,導致 GPU DMA 操作的延遲波動極大。對於效能敏感的 GPU 工作負載,務必同時啟用 CPU Pinning 和 HugePages。
限制與注意事項
PCI Passthrough 限制
| 限制 | 說明 | 影響 |
|---|---|---|
| 不支援 Live Migration | VFIO 裝置狀態無法被序列化 | VM 無法在線遷移至其他節點 |
| IOMMU Group 約束 | 同 group 裝置必須整組直通 | 可能需要直通不需要的裝置 |
| 驅動綁定要求 | GPU 必須綁定至 vfio-pci | 主機無法使用該 GPU |
| Guest 驅動 | Guest OS 需安裝對應 GPU 驅動 | 需準備含驅動的映像 |
vGPU 限制
| 限制 | 說明 | 影響 |
|---|---|---|
| 有限的 Live Migration | 僅支援單一 vGPU 的 VM | 多 vGPU VM 無法遷移 |
| Feature Gate | 需啟用 vGPU live migration feature gate | 非預設啟用 |
| Profile 互斥 | 同一 GPU 不可混用不同類型的 Profile | 規劃需統一 |
| 授權要求 | NVIDIA vGPU 需要有效的授權伺服器 | 需要額外基礎設施 |
主機前置條件
# 1. 確認 IOMMU 已啟用
dmesg | grep -e DMAR -e IOMMU
# 預期輸出: DMAR: IOMMU enabled / AMD-Vi: IOMMU performance counters supported
# 2. 確認 kernel 參數包含 IOMMU 設定
cat /proc/cmdline | grep iommu
# Intel: intel_iommu=on iommu=pt
# AMD: amd_iommu=on iommu=pt
# 3. 確認 GPU 已綁定至 vfio-pci 驅動
lspci -nnk -s 3b:00.0
# Kernel driver in use: vfio-pci ← 正確
# Kernel driver in use: nvidia ← 需要先解綁
# 4. 查看 IOMMU group
find /sys/kernel/iommu_groups/ -type l | sort -V | grep "3b:00"
# 5. 確認 /dev/vfio 裝置存在
ls -la /dev/vfio/驅動綁定注意
將 GPU 綁定至 vfio-pci 後,主機將無法使用該 GPU。若該 GPU 是主機唯一的顯示裝置,將導致主機失去圖形輸出。建議在無頭伺服器(headless server)上操作,或確保有其他 GPU 供主機使用。
VMware 對照表
以下表格對比了 VMware 與 KubeVirt 在 GPU 虛擬化各面向的實作差異:
| 功能 | VMware | KubeVirt |
|---|---|---|
| GPU 直通 | DirectPath I/O | VFIO PCI Passthrough |
| vGPU | NVIDIA GRID vGPU Profile | mdev + Device Plugin |
| 裝置管理 | vCenter → Host → PCI Devices | PermittedHostDevices CR |
| 資源調度 | DRS with GPU affinity | Kubernetes Device Plugin + Topology Manager |
| Live Migration | 不支援(DirectPath I/O) | 不支援(VFIO);有限支援(vGPU mdev) |
| vGPU Profile 設定 | vCenter GUI / Host Profile | KubeVirt CR mediatedDevices config |
| NUMA 感知 | 自動 | Device Plugin TopologyInfo + Kubelet |
| 裝置健康監控 | vCenter alarms | Device Plugin ListAndWatch health check |
| 多 GPU 支援 | 多 DirectPath I/O 裝置 | 多個 gpus / hostDevices 項目 |
| 驅動管理 | ESXi VIB 安裝 | 主機 kernel module + Guest 內安裝 |
遷移指南
從 VMware 遷移至 KubeVirt 時,GPU 相關的配置轉換通常遵循以下流程:
- 在 vCenter 中記錄 GPU 型號與 PCI ID(
vendor:device) - 在 KubeVirt CR 的
permittedHostDevices中設定相同的 PCI ID - 將 VMware VM 的 DirectPath I/O 設定對應到 KubeVirt VMI 的
gpus欄位 - 將 vGPU Profile 名稱(如 "grid_t4-1q")對應到
mdevNameSelector
故障排查
常見問題
# 裝置未出現在 Node 的 allocatable 資源中
kubectl get node <node> -o json | jq '.status.allocatable' | grep nvidia
# 確認 Device Plugin Pod 是否正常運行
kubectl get pods -n kubevirt -l app=virt-handler
# 檢查 virt-handler 日誌中的 Device Plugin 錯誤
kubectl logs -n kubevirt <virt-handler-pod> | grep -i "device\|plugin\|gpu\|mdev"
# 確認 Device Plugin socket 是否存在
ls -la /var/lib/kubelet/device-plugins/kubevirt-*.sock常見錯誤訊息
"no available host devices for resource"— 檢查 PermittedHostDevices 設定與節點上的實際裝置是否匹配"device is not bound to vfio-pci driver"— 需將 GPU 驅動從 nvidia/nouveau 切換至 vfio-pci"IOMMU group not found"— 確認主機 BIOS 和 kernel 已啟用 IOMMU